Enhancing Large Language Models: A Deep Dive into RAG LLM Technology
If you’re asking how to enhance the responses of Large Language Models (LLMs), Retrieval Augmented Generation (RAG) might be the answer. RAG LLM technology directly addresses the challenge of ‘hallucinations’ in AI responses and the need for dynamic, accurate knowledge. In this piece, we explore how RAG LLM leverages external data to improve the quality and reliability of LLMs, ensuring they remain up-to-date and factual.
Key Takeaways
Retrieval Augmented Generation (RAG) enhances Large Language Models (LLMs) by integrating external knowledge from databases to improve response accuracy and reduce information gaps.
Modern RAG systems use advanced retrieval and augmentation methods to provide dynamic, contextually relevant data to LLMs, thus producing more reliable and precise outputs for various applications.
RAG systems face challenges including the complexity of integration and data security, with ongoing research focused on refining RAG with strategies like active retrieval to improve long-form generation and ensure accuracy.
Understanding RAG for LLMs
At the core, Retrieval Augmented Generation (RAG) is a design approach that enhances Large Language Models (LLMs) by integrating external knowledge in the form of databases. This integration enables RAG to tackle issues inherent in LLMs, such as domain knowledge gaps and hallucination, where the model generates plausible but incorrect information. By providing LLMs with precise, up-to-date, and relevant information, RAG significantly improves response quality, ensuring that generated responses are grounded in factual information.
RAG works using a language model-generated query to retrieve relevant information from a database. This data is then incorporated into the model’s input to improve text generation. By employing vector databases, RAG can efficiently search for and retrieve relevant documents that enhance generation quality. The knowledge base used in RAG serves as a repository of factual information, which plays a pivotal role in creating well-informed and precise text output.
The Need for RAG in LLMs
Large Language Models (LLMs) often face the challenge of hallucination, where they generate plausible but incorrect or nonsensical information. This poses a significant obstacle to their effective use in real-world applications. Retrieval Augmented Generation (RAG) addresses this issue by:
Retrieving and using external evidence
Reducing the likelihood of generating incorrect content
Integrating external crowd-sourced knowledge like databases
Filling the domain knowledge gaps inherent in LLMs
Substantially improving their utility
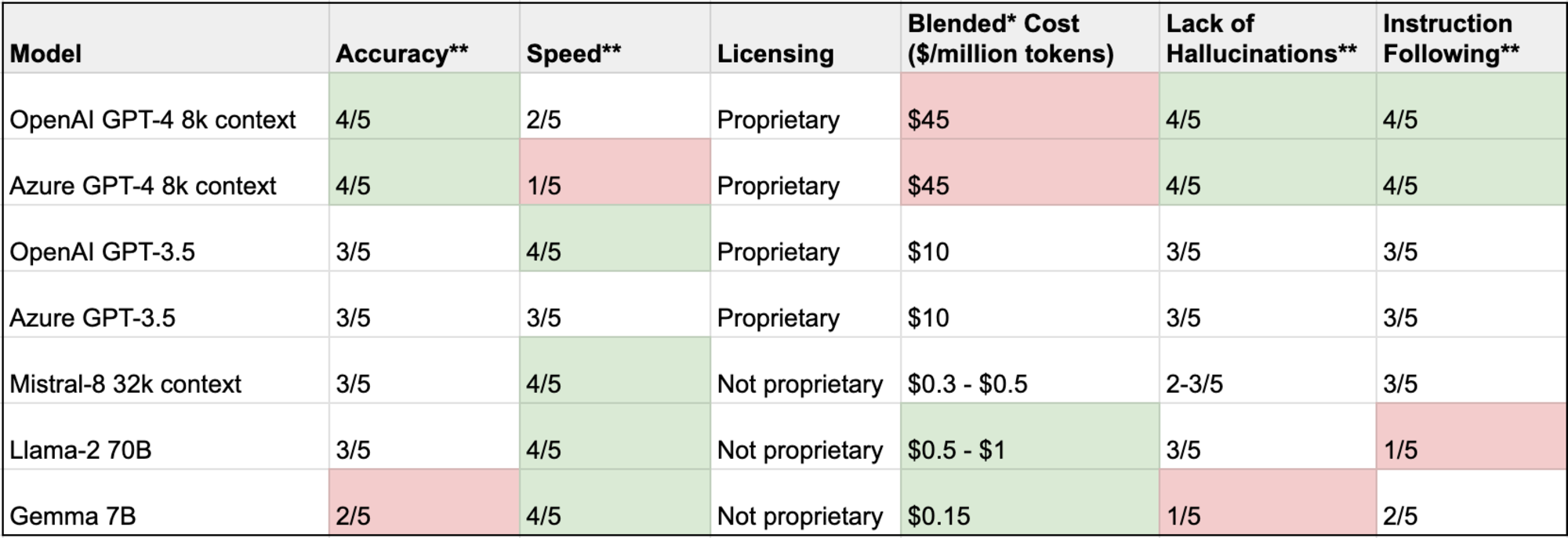
LLMs can also struggle to cope with changing or updating information. They may not effectively incorporate the latest knowledge without external support, limiting their usefulness in fast-evolving environments. In such scenarios, RAG enhances LLM performance by leveraging up-to-date evidence to inform the generation process. This allows RAG-equipped LLMs to stay relevant and accurate, even in environments that undergo rapid changes. Check out our study of how different LLMs compare when evaluated against customer support automation data.
How RAG Works with LLMs
The retrieval mechanism in a RAG system is designed to fetch information that is pertinent to the user’s query. This ensures that the information provided back to the model is contextually appropriate for generating coherent responses. Augmentation in RAG systems involves incorporating this relevant data, retrieved in real-time, into the user input or prompts. This provides context-rich information that might not be included in the LLM’s original training set, thereby enhancing the quality of generated responses.
Furthermore, RAG systems enhance the quality of responses from the generation component by utilizing both the newly acquired context-specific knowledge and the LLM’s original training data. This process tailors responses to be more accurate and relevant to the user’s query, significantly boosting the system’s performance in real-world applications.
Evolution of RAG Systems
The evolution of Retrieval-Augmented Generation (RAG) paradigms has been well chronicled in comprehensive review papers, contributing to our understanding of the progression of RAG systems. The journey of RAG systems can be seen transitioning through three main paradigms: Naive RAG with basic processes, Advanced RAG with improved retrieval strategies, and Modular RAG with adaptable modules for specific challenges. The evolution was driven by the desire to enhance the performance of LLMs, with RAG models being combined with powerful fine-tuned models like ChatGPTMixtral for superior results.
Modern RAG models have pushed the boundaries of augmentation and generation in LLMs by exploring hybrid methodologies and self-retrieval. These advanced RAG models focus on addressing issues such as:
improving retrieval quality
optimizing data indexing
utilizing embedding model techniques
post-retrieval processes
The incorporation of these advanced features and strategies has significantly improved the capabilities of RAG systems, making them an integral part of modern AI applications.
Early RAG Approaches
The early approaches of Retrieval Augmented Generation (RAG) were somewhat rudimentary in their operations and faced several challenges. One of the main issues was low precision in the retrieval component, which often fetched irrelevant information. This low precision affected the quality of the generated responses, making them less accurate and useful. Furthermore, recall issues in initial RAG systems meant they frequently missed important content that was pertinent to the query, leading to incomplete or misleading responses.
Redundancy in responses was another common issue with early RAG methods, resulting in the production of repetitive and verbose output. Moreover, these early systems heavily depended on the content they retrieved. This dependence meant that the quality and accuracy of the generated text were directly influenced by the retrieved content, making the systems less reliable and consistent.
Modern RAG Systems
In contrast to the early approaches, modern RAG systems have introduced several enhancements that have significantly improved their performance. One such enhancement is fine-grained indexing, which improves the granularity of data retrieval. This results in more accurate and relevant responses, enhancing the overall quality of the generated text. Modern RAG systems also utilize dynamic techniques, such as Sentence-Window Retrieval and Auto-Merging Retrieval. These techniques enhance RAG models by retrieving broader contexts or combining multiple sources, thereby improving response context relevance and accuracy.
The flexible architectures of modern RAG systems allow for module substitution or reconfiguration, making them adaptable to various applications. This flexibility, along with the introduction of specialized modules for retrieval and processing, has significantly enhanced the capabilities of RAG systems. Enhancements in the domain adaptation of RAG models are expected to refine their performance further by generating more accurate and contextually relevant responses.
Modern RAG systems are also tailored to meet the needs of companies with large proprietary datasets, thereby providing custom text-based AI solutions that are highly beneficial in business contexts.
Building a RAG System: Key Components

A RAG system comprises three key components: Retrieval, Generation, and Augmentation. Each component plays a critical role in enhancing the performance of Large Language Models (LLMs), making RAG systems highly effective and reliable. The retrieval component is responsible for fetching highly relevant context from a data retriever to inform the generation process. This process ensures that the generated responses are contextually appropriate and accurate, significantly enhancing the system’s performance.
Modern RAG systems have the following components:
Retrieval: designed to pull up-to-date information dynamically from external sources
Generation: reduces the need for continuous model training and parameter updates
Augmentation: makes RAG systems cost-effective and efficient
The combination of these three components makes RAG systems a powerful tool in the field of AI, particularly for tasks that require the generation of coherent and precise responses.
Retrieval Component
In a RAG system, the retrieval component plays a crucial role in fetching highly relevant context from data sources. This component uses relevancy searches and prompt engineering techniques to effectively interact and integrate with large language models. User queries are converted into vector representations to match with embeddings in a vector database containing the knowledge base, ensuring that the retrieved information has contextual relevance to the user’s query.
The retrieval process is enriched by multiple external data sources such as APIs, databases, or document repositories. These sources provide the private and proprietary data required for the retrieval component to function effectively. Semantic retrieval, which allows the inclusion of enterprise data into open-source models, further enhances the accuracy and personalization of applications like advanced chatbots and content recommendation systems.
Generation Component
The generation component of a RAG system is tasked with:
Converting the retrieved information into coherent text for the final output
Ensuring that the generated responses are clear, precise, and contextually appropriate
Integrating the relevant information retrieved by the retrieval component to enhance the quality of the generated text.
This seamless integration of retrieval and generation also ensures that the generated responses are tailored to the user’s query. This tailoring process makes the generated responses more relevant and useful, enhancing the user experience and the overall performance of the RAG system.
Augmentation Component
The augmentation component of an RAG system refines the context for the language model. This component uses the retrieved information to improve the prompt, which then guides better response generation. Augmentation data for RAG systems can come from a variety of sources, including unstructured text, structured information, and previously generated outputs from Large Language Models themselves.
By integrating context from relevant data, RAG systems are better equipped to reduce AI hallucinations during response generation. This is particularly beneficial in enterprise environments where errors can be highly consequential. Furthermore, the contextual augmentation offered by RAG systems effectively tackles the inability of traditional Large Language Models to understand domain-specific terminology and provide problem-specific data.
Comparing RAG and Fine-Tuning

Retrieval Augmented Generation (RAG) and fine-tuning each offer unique benefits in enhancing Large Language Models (LLMs). RAG is particularly advantageous for integrating fresh external knowledge into LLMs while fine-tuning refined models through internal knowledge improvement and refining output formats. Fine-tuning involves using a specialized corpus to refine a pre-trained model’s performance for a particular domain or task. During this process, precise adjustments to an LLM’s internal parameters align the model more closely with domain-specific contexts, thereby enhancing its performance.
One significant advantage of RAG is that LLMs equipped with RAG do not need to be retrained for specific tasks. This feature makes RAG a cost-effective solution by removing the need for frequent model retraining, which is particularly advantageous for businesses. When RAG is integrated with fine-tuning, it can address the limitations inherent to each method individually, resulting in more accurate and detailed responses to complex queries.
Assessing RAG Performance

The performance of Retrieval-Augmented Generation (RAG) systems is assessed using various metrics based on different aspects. These aspects include:
Ground truth: answer correctness and semantic similarity are key metrics when a ground truth is available.
Absence of ground truth: in scenarios where no ground truth exists, tools like the RAG Triad and TruLens-Eval are used to assess the system’s performance.
Large language model (LLM) specific responses: additional metrics may be used to evaluate the quality and relevance of LLM-generated responses.
Metrics specific to evaluating LLM responses include friendliness, harmfulness, conciseness, coherence, and helpfulness. The primary quality scores used in an RAG framework measure context relevance, answer faithfulness, and answer relevance. Furthermore, the adaptability and efficiency of RAG systems are assessed through metrics like noise robustness, negative rejection, information integration, and counterfactual robustness. These assessment methods provide a comprehensive evaluation of RAG performance, offering valuable insights into the system’s strengths and areas for improvement.
Challenges and Future Directions in RAG Research
While the advancements in Retrieval-Augmented Generation (RAG) are promising, the field of RAG research also faces several challenges. Some of these challenges include computational and financial costs, such as:
Building and integrating retrieval pipelines in enterprise applications, pose significant challenges and require effective combination with knowledge bases and insight engines.
Indexing, embedding, and pre-processing enterprise data for RAG systems, which are hampered by data sprawl, ownership issues, skillset gaps, and technical restrictions.
Ensuring the security of sensitive data during RAG implementations is a major concern for organizations.
Looking forward, active retrieval strategies, where LLMs seek auxiliary information only when lacking knowledge, offer a promising approach to refine long-form generation in RAG systems for such knowledge-intensive tasks. Other future research directions for RAG include reducing the risk of sensitive data exposure and generating more accurate information through the use of external fact-checking. These challenges and future directions highlight the ongoing evolution of RAG and its potential to revolutionize the field of AI.
Essential Tools for Developing RAG Systems
Developing effective Retrieval-Augmented Generation (RAG) systems requires the use of certain essential tools. Some of these tools include:
LangChain: a development framework that simplifies the creation, monitoring, and deployment of LLM-powered applications.
LangSmith: enhances developer productivity through streamlined debugging, testing, deployment, and monitoring workflows. It is part of the LangChain ecosystem.
LangServe: supports the easy deployment of applications with features such as parallelization and asynchronous API endpoints.
These tools are crucial for building and optimizing RAG systems.
LangChain includes the following tools for visual monitoring and evaluation capabilities:
TruLens-Eval: a tool offering browser-based analysis of RAG applications
LlamaIndex: provides a robust AI framework that includes tools for assessing the performance of applications built within its system
LlamaHub: the community hub of LlamaIndex, enriches developer collaboration by offering connectors, tools, datasets, and other resources.
With these tools, developers can effectively build, monitor, and deploy RAG systems, thereby enhancing their ability to create powerful AI applications.
Case Studies: RAG in Action
Retrieval-Augmented Generation (RAG) has been successfully applied in a number of industries, revolutionizing their processes and enhancing customer engagement. In healthcare, RAG has enabled higher accuracy and speed in contexts such as preoperative medicine. A specialized RAG model using 35 preoperative guidelines even exceeded junior doctors’ performance, achieving an accuracy of 91.4% versus the doctors’ 86.3%. RAG’s application extends to medical diagnostics, where it aids in anomaly detection in health scans, presenting a major leap forward.
The industrial sector has also greatly benefited from RAG integrations. In this sector, RAG powers digitalization optimizes design, and expedites manufacturing. The advancement of multimodal LLMs has been bolstered by RAG, facilitating advanced interactions through text, speech, and images.
In the retail industry, generative AI shopping advisors, supported by RAG, are revolutionizing the industry by enhancing customer engagement with a human-like shopping experience.
Recent Advances in RAG Research
Recent advances in Retrieval-Augmented Generation (RAG) research provide key insights and highlight critical developments in the field. Recent papers in RAG research introduce a comprehensive evaluation framework along with benchmarks. These developments advance our understanding of RAG system performance, thereby contributing to the continual improvement and refinement of RAG systems.
These advances in RAG research not only provide valuable insights into the field but also pave the way for future developments. By continually pushing the boundaries of what is possible with RAG, researchers are ensuring that RAG remains at the forefront of AI developments, offering exciting possibilities for the future of AI applications.
Leveraging RAG and LLM for Customer Support Automation
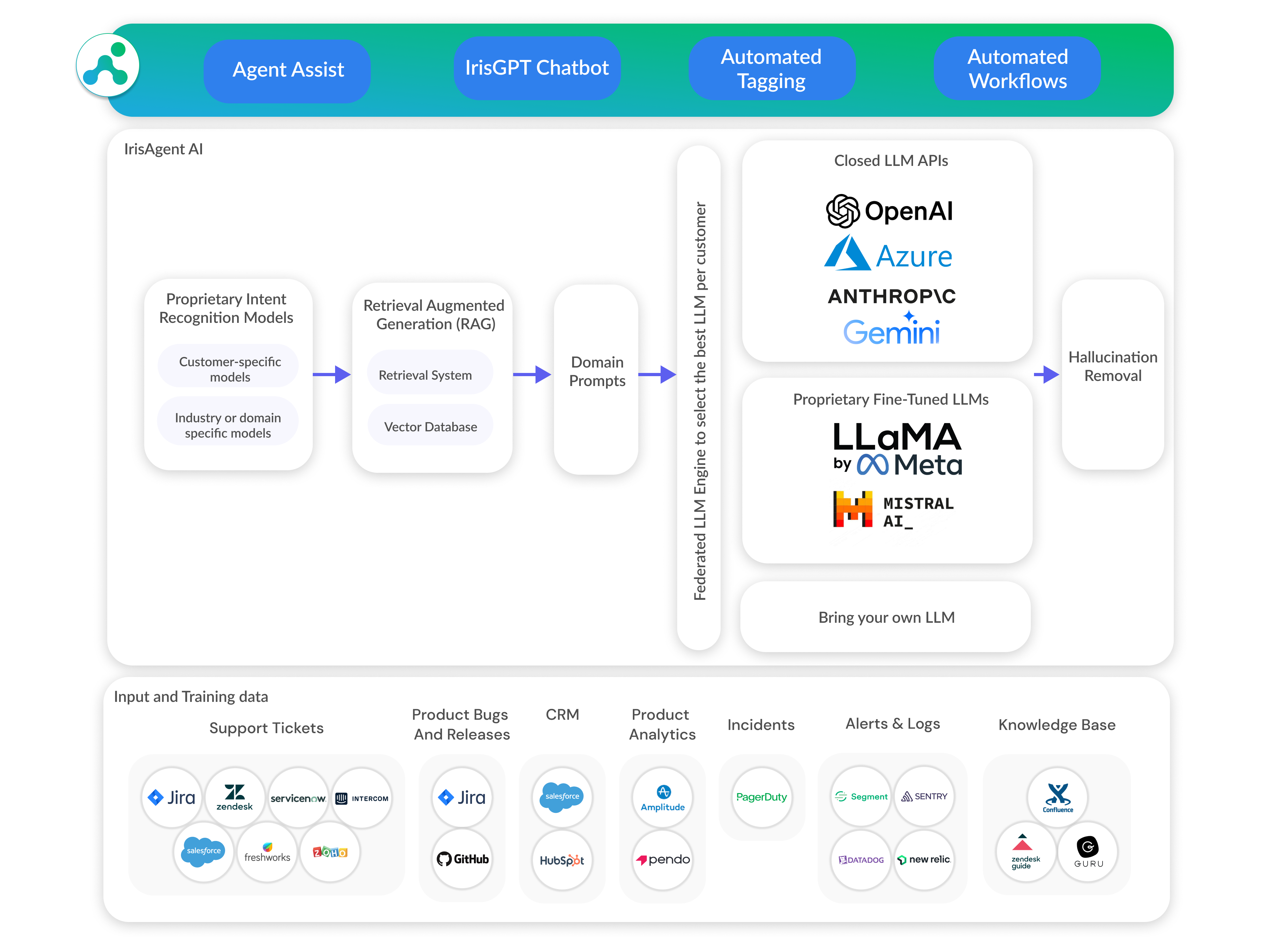
Retrieval Augmented Generation (RAG) and Large Language Models (LLMs) technologies can be leveraged for customer support automation, providing a more efficient and effective customer service experience. For instance, IrisAgent leverages the latest AI technologies to deflect support queries. By integrating RAG and LLM technologies, the system can effectively handle a large volume of customer queries, providing quick and accurate responses.
The integration of RAG and LLM technologies in customer support automation significantly enhances AI-powered support systems. By providing precise and up-to-date responses, these systems can effectively address customer queries, reducing the workload on human agents and improving customer satisfaction.
As such, RAG and LLM technologies are set to revolutionize the field of customer support automation, offering exciting possibilities for businesses and customers alike.
Summary
In summary, Retrieval Augmented Generation (RAG) is an innovative approach that enhances Large Language Models (LLMs) by integrating external knowledge, addressing issues like hallucination and domain knowledge gaps, and improving response quality with up-to-date, relevant information. RAG systems have evolved from early approaches with limitations to modern systems with improved retrieval strategies and adaptable modules for specific challenges. Despite the challenges, the field of RAG research is full of potential, with future directions including active retrieval strategies and reducing sensitive data exposure. By leveraging RAG and LLM technologies, businesses can revolutionize their customer support automation, enhancing customer engagement and improving overall business performance.
Frequently Asked Questions
What is Retrieval Augmented Generation (RAG)?
Retrieval Augmented Generation (RAG) is a design approach that enhances Large Language Models (LLMs) by integrating external knowledge in the form of databases, improving response quality by providing precise, up-to-date, and relevant information.
What are the key components of a RAG system?
The key components of a RAG system are Retrieval, Generation, and Augmentation. These components work together to fetch relevant context, convert it into coherent text, and refine the context for the language model.
How has RAG evolved over time?
RAG systems have evolved through three main paradigms: Naive, Advanced, and Modular, and modern models are exploring hybrid methodologies and self-retrieval to push the boundaries of augmentation and generation in LLMs. This has enabled them to become more adaptable to specific challenges.
What are some applications of RAG in different industries?
RAG has diverse applications across industries. In healthcare, it improves preoperative medicine and medical diagnostics. In the industrial sector, RAG enables digitalization, design optimization, and faster manufacturing. Generative AI shopping advisors in the retail industry also benefit from RAG, enhancing customer engagement.
What are the future directions in RAG research?
In the future, RAG research may focus on active retrieval strategies for LLMs and reducing the risk of sensitive data exposure, as well as generating more accurate information through external fact-checking. These directions aim to enhance the performance and privacy of RAG systems.