Best LLMs for Customer Support Chatbots in 2026
Well, like everything in life, it depends. We offer a customer support automation platform and spend a large amount of our time and resources in evaluating, benchmarking, and deploying the most optimal Generative AI models for our customers. In this article, we share our learnings and takeaways in evaluating the popular Large Language Models (LLMs), particularly in the domain of customer support automation: LLama 2, Mistral, GPT-4, and GPT-3.5—these are flagship models representing the latest advancements in AI. This includes general-purpose chatbots like ChatGPT and Google Gemini, as well as customer service chatbots that are trained on a business’s docs and data. Ongoing AI research, including efforts from organizations like LG AI Research, Google, and Anthropic, continues to drive the development and improvement of these models. We also evaluated the performance of these best LLMs across different providers such as OpenAI, Azure, and other emerging provider platforms.
Introduction to Large Language Models
Large language models (LLMs) are a groundbreaking advancement in artificial intelligence, designed to process, understand, and generate human language with remarkable fluency. Trained on massive volumes of textual data, these models excel at interpreting user input and producing coherent, contextually relevant responses. LLMs have become the backbone of modern natural language processing, powering a wide range of conversational AI systems, from chatbots to virtual assistants. Their ability to learn from diverse datasets enables them to adapt to various real-world scenarios, making them indispensable for applications such as customer service, language translation, and content summarization. As LLMs continue to evolve, they are setting new standards for how artificial intelligence interacts with people, delivering more natural and effective communication across industries.
Evaluation Criteria
While there are several benchmarks, evaluation methods, and results available online when it comes to the out-of-the-box performance of popular LLMs, we wanted to evaluate specifically for the customer support domain. Natural language processing (NLP) plays a crucial role in this evaluation by enhancing the LLMs’ ability to interpret user inputs, understand context, and generate accurate and contextually relevant responses. In our evaluation process, we also consider advanced features such as domain-specific assessments and debugging tools, which provide deeper insights beyond basic testing. Additionally, advancements in language modeling are a key factor in assessing the effectiveness of LLMs for customer support. We prioritized certain dimensions: Accuracy, Speed, Proprietary, Cost, Lack of Hallucinations, and Instruction Following.
Accuracy
Accuracy and correctness of responses are the most impactful elements for us and our customers as we are not just building demo chatbots but actual products that take user feedback and are deployed in production. We value our customers’ brand and trust highly and ensure that only accurate answers without hallucinations are generated, especially in varying conversational contexts. Delivering relevant information is crucial for customer trust and satisfaction, as users rely on chatbots to provide precise and pertinent data.
Most companies use AI chatbots along with a Retrieval-Augmented Generation (RAG) setup. It’s important that the results are only produced from AI tools using whitelisted information sources and reference data that have been fed into the RAG.
Speed
Our customers deploy our AI solutions in production as either AI chatbots, autonomous agents, or agent augmentation solutions and care about support KPIs and evaluation metrics such as first response times and total resolution times. As a result, quick and fast responses are critical for ensuring a good customer experience.
If you are building a real-time customer-facing AI chatbot, then speed matters. Smaller LLMs (less than 10B parameters) are noticeably faster and deliver efficient performance in real-time applications, producing results in order of milliseconds. While larger LLMs take a few seconds. This difference really impacts the usability and customer experience of a chatbot. However, if you are processing a batch workload and are not expected to have real-time results, this evaluation criteria becomes moot.
Proprietary vs non-proprietary models
Non-proprietary and/or open-source LLMs offer the advantage of transparency, allowing developers and researchers to scrutinize, modify, and improve the model’s code, which fosters innovation and community collaboration. The open source nature of these models also provides greater accessibility and flexibility, enabling third-party developers to build and customize AI applications more easily. On the other hand, proprietary LLMs, maintained by private entities, are considered closed models and can ensure tighter control over security and intellectual property, potentially offering more stable and reliable solutions for commercial applications. In addition, domain-specific LLMs are tailored for specialized industries, further advancing precision and efficiency.
There are only two providers of proprietary, closed models of GPT-4, OpenAI and Azure (surprisingly, their performance characteristics are not identical). Then, there are non-proprietary models like Llama (from the Meta AI team), Mistral, and Gemma with open weights and more permissive licensing. If you are using a hosted provider for these models, you can shop around and have more options available.
Cost
Depending on whether you use a proprietary model or not accessible and whether you are hosting yourself or using a provider, the costs and the costing dimensions may be different. For the former, you pay a per-token cost. If you are using a hosted provider (for proprietary or non-proprietary models), they will likely charge per token. Note that, given there are only two providers for the proprietary model, you are likely to pay much higher compared to hosted providers for non-proprietary models. For example, the costs for Mistral are 1/100th of GPT-4 (not to discount the fact that in our analysis, the latter performs better) and 1/10th of GPT-3.5. Alternatively, if you are hosting a non-proprietary model in your infrastructure, the costs include GPU costs and the engineering costs to manage the infrastructure. The required computational power for running advanced models like GPT-4 significantly impacts both infrastructure and GPU costs.
Lack of Hallucinations
The percentage of times when the model’s response was a hallucination. I’d like to distinguish hallucination from accuracy. A response can both contain accurate information and hallucination at the same time. Our criteria were pretty simple - any tangible piece of information should come from the shortlisted sources of information.
Further training and fine-tuning of large language models can help reduce hallucinations and improve the reliability of their responses.
Instruction Following
Many times, LLMs need to follow instructions correctly. For instance, the LLM system sometimes might introduce a text/phrase that it was explicitly asked not to, etc. Most people use LLMs with RAG and want structured information (e.g. JSON, YAML, CSV) and it’s important to follow the instructions and return the asked structured format. So be careful when using different models. For example, Llama-2 is not instruction fine-tuned, while Llama-2 inst is instruction fine-tuned and is better at following instructions.
Evaluation Setup
Evaluation data set
We hand-crafted an evaluation data set based on our experience of automating customer support queries through chatbot and email bot. Our dataset contained queries that can be answered based on support FAQs and knowledge articles. Deep research was conducted to ensure the dataset's quality and relevance. It included data points from different industries and varying question complexity. We ran different models against this hand-crafted and high-quality evaluation data set.
Prompts
We kept the prompts the same across all these models. The prompts that were selected for the evaluation process have demonstrated tremendous success in automating a large volume of both simple and complex support queries. In fact, just a couple of well-designed prompts can yield significant insights into model performance.
Models and Providers
We evaluated the performance of different combinations of models and providers. We found scenarios where the same models, such as GPT-4, across different providers (e.g. Azure and OpenAI), gave different results. This highlighted that the same models can yield varying outcomes depending on the provider. Additionally, we also evaluated other models beyond the most popular ones to gain a broader perspective. This was crucial for assessing the performance of large language models (LLMs) to measure and compare their capabilities.
Large Language Models Evaluation Results
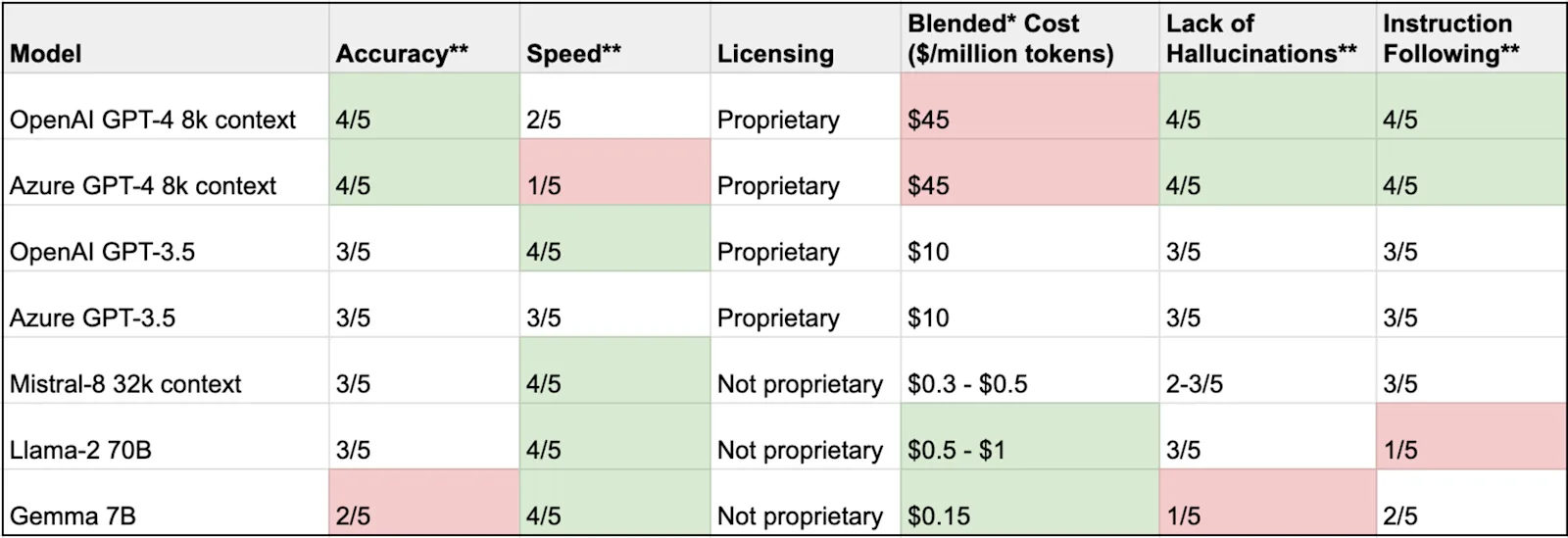
* Blended cost is the average of input and output token cost
** Scale of 1-5 where 5 is the highest and 1 is the lowest
When evaluating model outputs, we prioritized the generation of coherent responses, as this is crucial for effective chatbot interactions. The ability to generate responses quickly and accurately was a key metric in our results summary.
Models with a larger context window demonstrated superior handling of complex queries, allowing them to process and reason over more extensive inputs. Multilingual support was a significant differentiator for some models, enabling broader applicability across different regions and markets.
Certain models stood out for their high performance in demanding scenarios, such as on-premises or private cloud deployments. Advanced capabilities, including emotion detection and multimodal input handling, were also noted in next-generation models, setting them apart with more human-like and sophisticated functions.
Some models enabled the creation of versatile chatbots capable of handling a wide range of tasks and queries. Notably, a few models combined all the features of previous generations, offering a comprehensive and unified solution for diverse AI applications.
Key Insights and Recommendations
The best AI model for a business serving clients with large ticket value
Who are you? Consider the below if you are an airline, a legal firm, or an enterprise B2B software business with a large ticket value (Annual Contract Value of $10K or more) and/or high legal risk. For such organizations, enterprise needs often dictate the choice of model, prioritizing efficiency, reliability, and profitability for specialized business requirements. You cannot tolerate inaccuracies, hallucinations, or security incidents. Remember how an airline was held liable for misinformation given to a consumer by an AI chatbot on its website and had to give damages?
Our recommendation: We recommend going with either of the below options:
Azure GPT-4 offered and managed by a trusted customer support vendor, or
An in-house non-proprietary fine-tuned model offered by a trusted customer support vendor (like us!) that has strong safeguards in place to prevent inaccuracies and hallucinations, or
Azure GPT-4 if you have the engineering bandwidth to train, deploy, and manage your own ML infrastructure (we wouldn’t take this responsibility lightly!). Note that we would still recommend against piping the queries directly to GPT-4, without a trusted safeguard engine, as you may be held liable for hallucinations.
When deploying AI chatbots in large organizations, these solutions are typically integrated into enterprise applications, where customization and security are critical.
Why? The risk-reward ratio of smaller LLMs is hard to justify and we would recommend larger models or fine-tuned smaller LLMs. Larger models offer advantages for high-value use cases, delivering better accuracy and reliability. From a security perspective, you may prefer sending data to Microsoft Azure, instead of a smaller company, OpenAI. Even though GPT-4 is the slowest and most expensive model, you get the highest accuracy and lowest hallucinations that you need. For the most advanced and innovative solutions, consider frontier models, which lead in performance benchmarks and drive AI innovation. You can achieve similar performance as GPT-4 when a trusted customer support vendor fine-tunes non-proprietary models (such as Mistral) on your high-value data.
The right model for a small or medium-sized business with a low ticket value
Who are you? Consider the below recommendation if you are a small e-commerce business built on top of Shopify, or you are a gaming company with many free/freemium customers, or you have a strong PLG (Product Led Growth) motion with many free/freemium customers, or you are a low to mid-end SaaS business. You get the picture.
Our recommendation: We recommend going with the below option:
A non-proprietary model (e.g. Mistral or Gemma) offered by a trusted customer support vendor that has strong safeguards in place to prevent inaccuracies and hallucinations. We wouldn’t recommend using this out-of-the-box without safeguards as you will run into more than 50% of responses resulting in hallucinations.
Why? High speed and low costs with reasonable accuracy and efficient performance are your ideal factors. Smaller, non-proprietary models deliver efficient performance, making them accessible and scalable for SMBs. Versatile chatbots built on these models can handle a wide range of queries and tasks, which is especially valuable for businesses with diverse customer needs. You don’t need to use the much slower and more expensive (10x) GPT-4 models. You can get reasonable accuracy with emerging non-proprietary models but with the right safeguards and hallucination detection models offered by trusted software vendors (like us!).
Hybrid
You do not fall in either of the two above buckets. In that case, the answer is likely a hybrid of the two recommendations above, which often involves leveraging different LLMs to balance performance, cost, and accuracy. We offer a free consultation (booking link) that helps you figure out the right model for your business.
Benefits of Using LLMs in Chatbots
Integrating large language models into chatbots unlocks a host of benefits that drive better customer engagement and operational efficiency. LLMs empower chatbots to tackle complex reasoning tasks, understand nuanced user queries, and deliver relevant responses with high accuracy. This advanced capability translates into more effective customer support, as chatbots can handle a broader range of inquiries and resolve issues faster. Additionally, LLMs can be fine-tuned for specialized tasks such as sentiment analysis, data analysis, and code generation, making them highly versatile for different business needs. Their ability to exhibit emotional intelligence and nuanced understanding further enhances the user experience, enabling chatbots to respond empathetically and appropriately in diverse situations. As a result, businesses leveraging LLM-powered chatbots benefit from improved customer satisfaction, streamlined support processes, and the ability to address advanced and complex customer needs.
Chatbot Development with LLMs
Building chatbots with large language models involves a strategic approach that starts with collecting relevant data, followed by model training and fine-tuning to meet specific requirements. The choice of LLM is crucial and depends on factors such as the complexity of user input, the desired response style, and the performance needs of the application. Popular models like GPT-4, GPT-5, and LLaMA are known for their superior performance, efficient processing, and innovative architecture, making them top choices for chatbot development. Open source models, readily available through platforms like Hugging Face Hub, offer additional flexibility by providing access to pre-trained models and a vibrant community for support and collaboration. Fine-tuning these models allows developers to tailor chatbot behavior to unique business needs, ensuring that the final solution delivers both efficiency and high-quality user interactions.
LLMs in Customer Service
Large language models have fundamentally changed the landscape of customer service by enabling the creation of intelligent customer service bots that operate around the clock. These AI-powered bots can manage a wide spectrum of customer queries, from straightforward questions to more complex issues, across multiple communication channels such as chat, email, and phone. By leveraging LLMs, businesses can significantly improve response times and deliver more personalized, human-like interactions, which boosts customer engagement and satisfaction. Furthermore, LLMs facilitate advanced sentiment analysis and feedback processing, helping organizations identify trends and areas for improvement in their customer support operations. As a result, LLM-driven customer service bots are now essential tools for companies aiming to enhance customer loyalty and deliver superior support experiences.
Future of LLMs in Chatbots
The future of large language models in chatbots is bright, with rapid advancements poised to further elevate the capabilities of conversational AI systems. Emerging trends include the integration of multimodal capabilities, allowing chatbots to process not just text but also images and speech, leading to richer and more interactive user experiences. The development of advanced reasoning models, particularly those utilizing reinforcement learning, promises to enhance the ability of LLMs to tackle complex tasks and deliver more accurate, context-aware responses. As artificial intelligence research continues to push the boundaries, we can expect LLMs to play an even greater role in virtual assistants, customer support, and workflow automation. These innovations will drive improved efficiency, deeper contextual understanding, and more meaningful interactions, shaping the next generation of AI chatbots and conversational AI solutions.
Our approach to GenAI chatbots
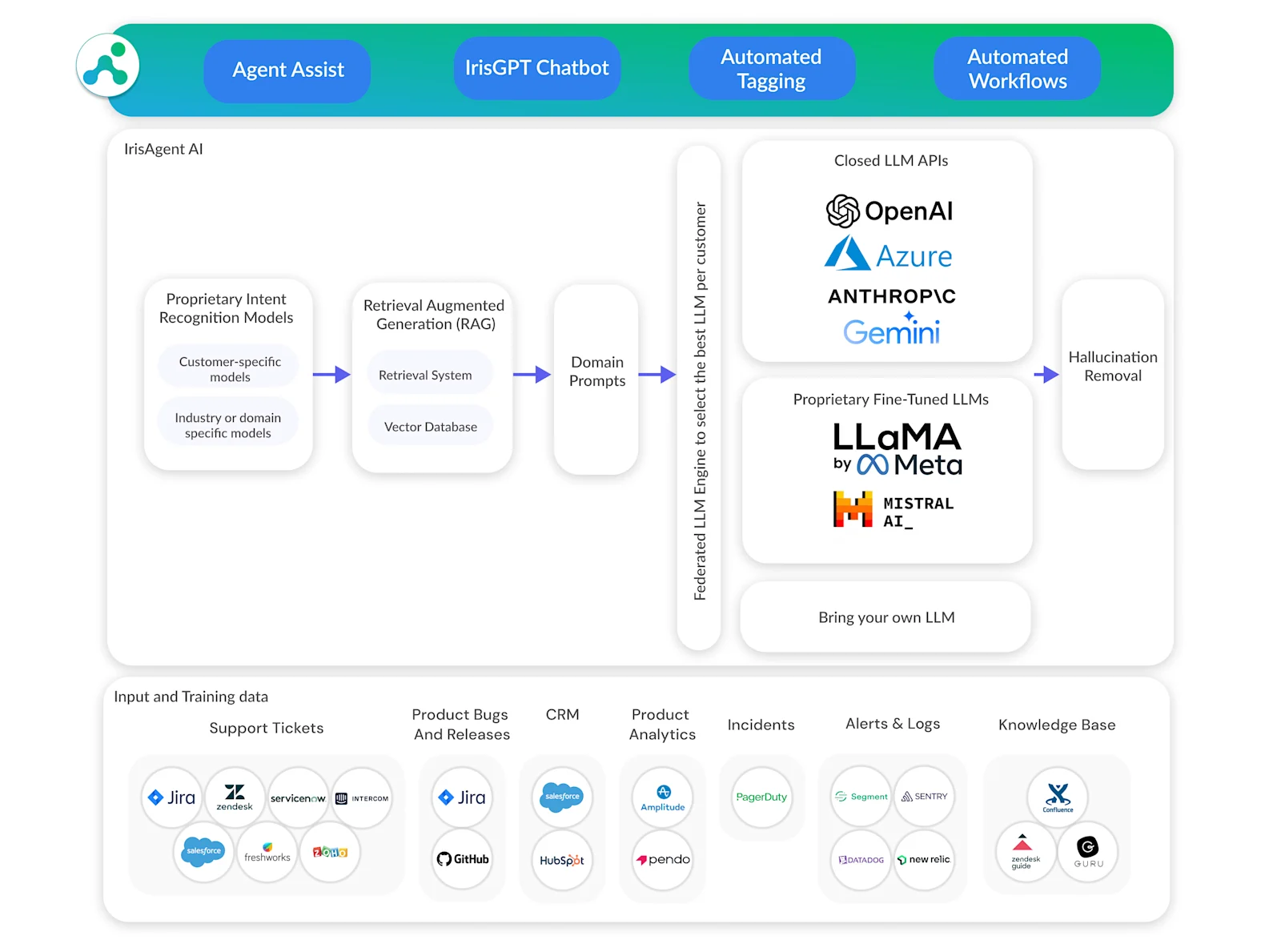
Our GenAI stack for building AI chatbots and ticket automation platforms includes multiple LLMs, a federation layer to select the best LLM, LLMs fine-tuned on customer-specific and domain-specific data, proprietary intent recognition models, RAG, domain-specific prompts, and hallucination detection and prevention. We also offer hosted model deployments in customers’ own premises for larger enterprises. We have found that smaller LLMs that have been fine-tuned on high-quality domain-specific data perform as well or even better than the more expensive and slower larger LLMs. Additionally, integrating search engines enhances the capabilities of AI chatbots by providing access to current events, links to sources, and real-time web results.
The LLM space in artificial intelligence is very exciting and fast-evolving. If you are on your own GenAI journey, evaluating different models, and training data, or looking for a trusted partner for your automation needs, we would love to chat with you!
Frequently Asked Questions
What is the best LLM for building a customer support chatbot?
The best LLM depends on your business profile. For high-ticket-value businesses (airlines, legal firms, enterprise B2B), GPT-4 via Azure offers the highest accuracy and lowest hallucination rates. For small and medium businesses with lower ticket values, non-proprietary models like Mistral or Gemma deliver high speed and low cost with reasonable accuracy — especially when paired with hallucination detection safeguards. Many businesses benefit from a hybrid approach that uses different LLMs for different query types.
How should you evaluate LLMs for customer support?
Evaluate LLMs for customer support across six key dimensions: accuracy and correctness of responses, speed of response generation, whether the model is proprietary or open-source, cost per token, hallucination rate (how often the model fabricates information), and instruction following (the model's ability to return structured output formats like JSON or YAML). Testing should use a domain-specific evaluation dataset, not general benchmarks.
What is the difference between proprietary and open-source LLMs for chatbots?
Proprietary LLMs like GPT-4 are closed-source models maintained by private companies (OpenAI, Azure) that offer tighter security and generally higher accuracy, but at a significantly higher cost. Open-source LLMs like LLaMA, Mistral, and Gemma offer transparency, flexibility, and lower costs — Mistral can be 1/100th the cost of GPT-4. Open-source models also let you shop across hosting providers and fine-tune on your own data.
How do LLM hallucinations affect customer support chatbots?
LLM hallucinations occur when a chatbot generates plausible-sounding but fabricated information not grounded in its source data. In customer support, this can lead to misinformation, loss of customer trust, and even legal liability — as seen when an airline was held liable for damages after its AI chatbot gave incorrect information. Reducing hallucinations requires using Retrieval-Augmented Generation (RAG) with whitelisted information sources and dedicated hallucination detection layers.
What is RAG and why is it important for AI chatbots?
RAG (Retrieval-Augmented Generation) is a technique where the AI chatbot retrieves relevant information from a curated knowledge base before generating a response, rather than relying solely on the LLM's training data. This ensures responses are grounded in approved, up-to-date source material such as support FAQs and knowledge articles, significantly reducing hallucinations and improving accuracy for customer support use cases.
Are smaller LLMs better than larger ones for chatbots?
Smaller LLMs (under 10 billion parameters) are significantly faster, producing responses in milliseconds compared to seconds for larger models, and cost a fraction of the price. For real-time customer-facing chatbots where speed matters, smaller models deliver noticeably better user experience. When fine-tuned on high-quality domain-specific data, smaller LLMs can match or even outperform larger, more expensive models like GPT-4 in accuracy.
How much do LLMs cost for customer support chatbots?
Costs vary dramatically by model type. Proprietary models like GPT-4 charge higher per-token rates through only two providers (OpenAI and Azure). Non-proprietary models like Mistral can cost as little as 1/100th of GPT-4 and 1/10th of GPT-3.5 when using hosted providers. Self-hosting open-source models involves GPU infrastructure and engineering costs instead of per-token fees. The right choice depends on balancing accuracy requirements against budget.
What is instruction following in LLMs and why does it matter?
Instruction following is an LLM's ability to adhere to specific formatting and behavioral rules in its prompts — for example, returning responses in JSON format, avoiding certain phrases, or staying within defined topic boundaries. This capability is critical for production chatbots that need structured outputs. Not all models are equally capable: for instance, base LLaMA-2 is not instruction fine-tuned, while LLaMA-2-Instruct is specifically trained for this purpose.
Can the same LLM perform differently across providers?
Yes. The same model can produce different results depending on the hosting provider. For example, GPT-4 on Azure and GPT-4 on OpenAI do not always deliver identical performance characteristics. This makes it important to benchmark your specific use case across providers rather than relying solely on the model name when making deployment decisions.
What is the best approach for enterprise AI chatbot deployment?
For enterprises, the recommended approach combines multiple LLMs with a federation layer that selects the best model per query, LLMs fine-tuned on domain-specific data, proprietary intent recognition, Retrieval-Augmented Generation (RAG), domain-specific prompts, and hallucination detection and prevention. Smaller LLMs fine-tuned on high-quality domain data can match or outperform larger models, offering better speed and cost efficiency at enterprise scale.


