
Google Cloud Run Vs. AI Platform Pipelines: Making ML Pipeline Choice
We are a customer support automation startup, IrisAgent, that processes large quantities of text data from support tickets and time-series data from engineering and product sources. Our business objective is to enable smarter customer support using real-time insights about operational, engineering, and user issues.
We evaluated the Google AI Platform and Google Cloud Run for setting up a robust and production-ready ML pipeline, focusing on the capabilities of the Cloud AI Platform. Hope our findings can save you valuable time.
Introduction
What is Google Cloud Run?
Google Cloud Run is a fully managed, serverless platform that allows developers to deploy containerized applications quickly and easily. It automatically scales applications in response to incoming requests, providing cost-efficiency and flexibility. Developers can focus on building and deploying code while Google Cloud Run handles the underlying infrastructure, making it ideal for web services, microservices, and API deployments.
What is Google AI Platform?
Google AI Platform is a cloud-based service that simplifies the development, training, and deployment of machine learning models. It provides a collaborative environment for data scientists and ML engineers, offering tools for data preparation, training, and serving models. Google AI Platform accelerates the development of AI solutions, making them accessible to a broader range of users. Additionally, the Cloud AI Platform Training service provides managed training capabilities, integrating seamlessly with other GCP services.
Introduction to ML Pipelines
Definition of an ML pipeline and its importance in the machine learning lifecycle
A machine learning (ML) pipeline is a series of automated processes that enable the efficient development, deployment, and maintenance of machine learning models. It is a crucial component of the machine learning lifecycle, as it streamlines the process of building, testing, and deploying models, allowing data scientists and engineers to focus on high-level tasks such as model development and improvement.An ML pipeline typically consists of several stages, including data ingestion, data preprocessing, feature engineering, model training, model evaluation, and model deployment. Each stage is designed to perform a specific task, and the output of one stage serves as the input to the next stage.
The importance of an ML pipeline lies in its ability to automate repetitive tasks, reduce errors, and improve the efficiency of the machine learning development process. By automating tasks such as data preprocessing and model training, data scientists and engineers can focus on higher-level tasks such as model development and improvement, leading to faster development cycles and better model performance.
Overview of the key components of an ML pipeline, including data ingestion, feature engineering, training, and deployment
The key components of an ML pipeline include:
Data Ingestion: This stage involves collecting and processing data from various sources, such as databases, files, or APIs.
Feature Engineering: This stage involves transforming and selecting the most relevant features from the ingested data to improve model performance.
Model Training: This stage involves training a machine learning model using the engineered features and a suitable algorithm.
Model Evaluation: This stage involves evaluating the performance of the trained model using metrics such as accuracy, precision, and recall.
Model Deployment: This stage involves deploying the trained model in a production environment, where it can be used to make predictions on new data.
Other important components of an ML pipeline include:
Data Preprocessing: This stage involves cleaning, transforming, and preparing the data for feature engineering.
Model Selection: This stage involves selecting the most suitable machine learning algorithm and hyperparameters for the problem at hand.
Model Monitoring: This stage involves monitoring the performance of the deployed model and retraining it as necessary.
Goals for our ML Pipeline
We wanted to move to an ML pipeline for the following objectives:
Easy to manage
We’d rather focus on our and our customers' core business problems than spend much time on data engineering and managing the ML pipeline. We wanted an out-of-the-box solution that just worked.
Modular and Extensible
We are a young startup and are iterating quickly on different ML approaches. We have different steps in the process of our ML pipeline and wanted a pipeline tool that allows us to swap out and replace new components easily.
Compatible with our current setup
We currently use containers on Google Cloud Run to deploy all our services and use MongoDB and Google Cloud Storage for storage.
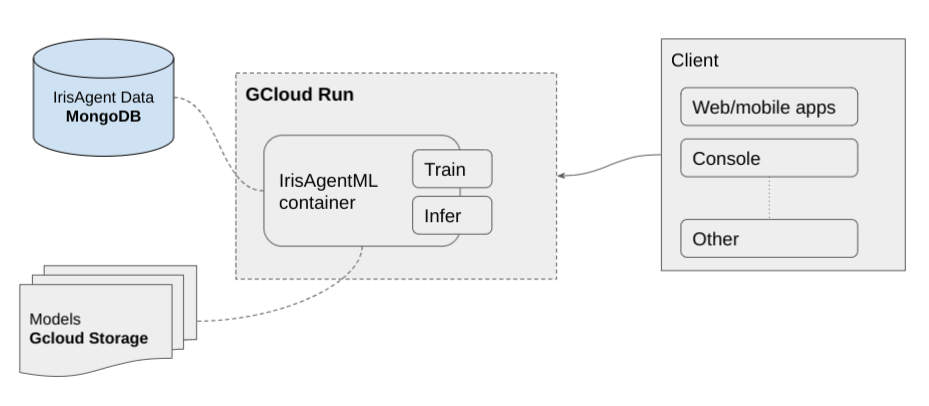
Ensuring the correct Google Cloud project configuration is crucial for seamless integration and management of our services.
ML pipeline requirements
The first thing we did was to define the ideal setup and our requirements. We wanted modular components for data preparation, processing, training, evaluation, and serving new data.
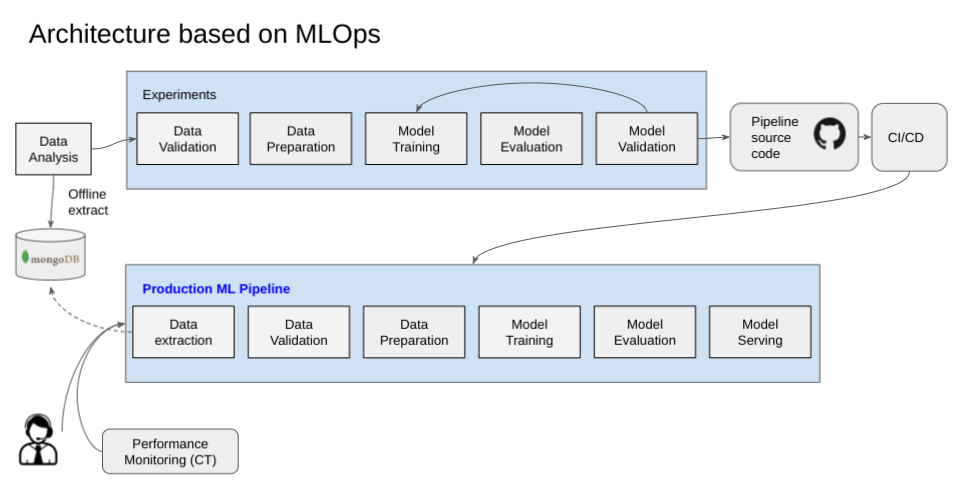
Findings to build Cloud AI Platform Pipelines
Google AI Platform
Google AI Platform was compatible with our current cloud setup which was also on GCP. The AI Platform Pipeline allows for the deployment and management of Kubernetes clusters and Kubeflow pipelines on GCP. It is a managed service, so it was easy to manage. However, we ran into a blocker when experimenting with it.
Let me shed some light on it. We had to decide between using a standard container or developing a custom container, and unfortunately, neither worked for us.
Standard Container
We could not use GCP’s standard out-of-the-box container as we used ML frameworks other than TensorFlow, scikit-learn, or XGBoost. As a customer-support AI company, we have several NLP models that often don’t use standard frameworks. We also needed to experiment and deploy models quickly without getting blocked by framework limitations.
While standard frameworks for predictions run smoothly on the Cloud AI Platform Prediction, non-standard frameworks required custom prediction routines. Standard frameworks for predictions run smoothly on the AI platform. However, a non-standard framework required us to configure a custom prediction routine impacting our velocity. The custom prediction routine also had a big limitation: we could only use a legacy (MLS1) machine type with available RAM of just 2GB! We very quickly ran into an out-of-memory issue. ISSUE: Bad model detected with error: Model requires more memory than allowed. Please try to decrease the model size and redeploy Thus, standard containers became a no-go.
ISSUE: Bad model detected with error: Model requires more memory than allowed. Please try to decrease the model size and redeploy
Custom Container
Next, we tried using a custom container, but it didn’t meet the speed and the easy-to-manage requirement we had. It also required a different deployment strategy.
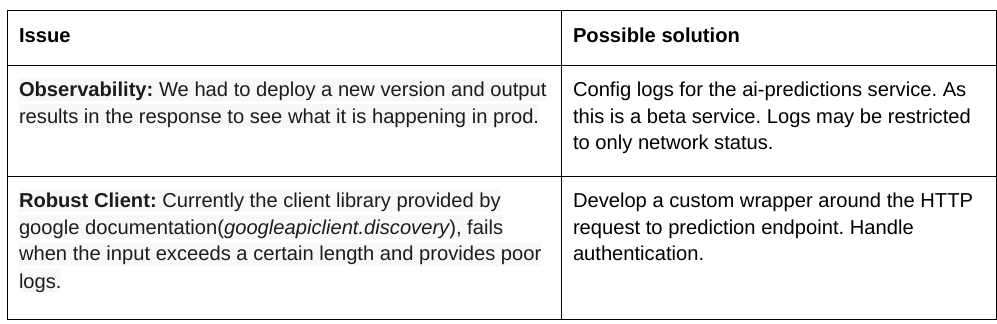
Google Cloud Run
We decided to stay with Cloud Run for our ML requirements. We set up a microservices-oriented architecture and used Cloud Scheduler to schedule different ML tasks periodically.
The most significant advantage of Cloud Run is it handles autoscaling and container crashing gracefully with no operational overhead on us. It is also much cheaper with a generous free tier. The most significant limitation of Cloud Run is max RAM of 8 GB and max CPU count of 4, which will likely be hit in the future as we use larger ML models. We will likely migrate to the AI Platform or Google Kubernetes Engine at that time.
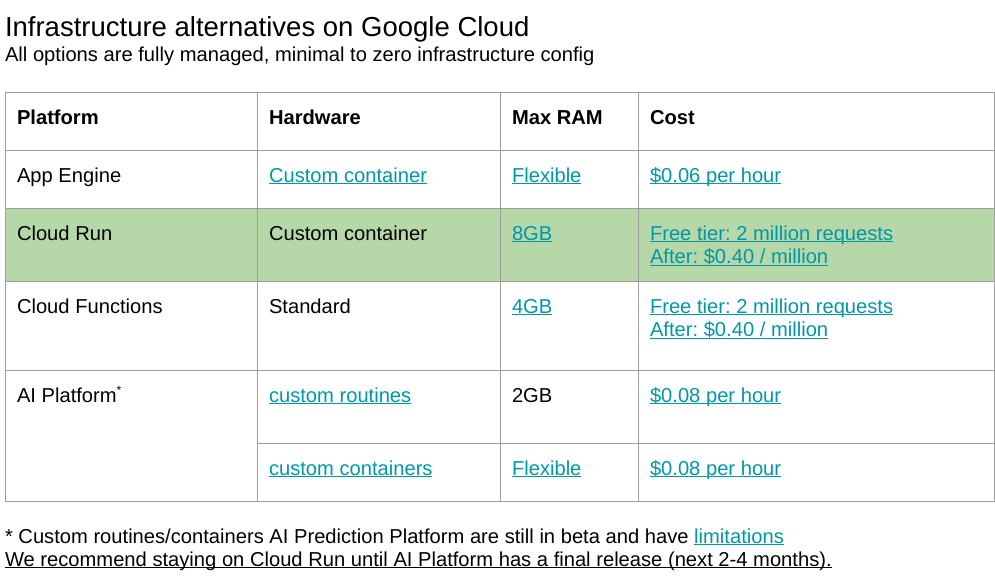
Platform Pipelines Comparison
Comparison of Google Cloud Run and AI Platform for ML pipelines, including features and limitations
When it comes to building and deploying machine learning pipelines, Google Cloud Run and AI Platform are two prominent options. Here’s a detailed comparison of their features and limitations:Google Cloud Run
Features:- Fully managed platform for building and deploying containerized applications.
Supports a wide range of programming languages and frameworks.
Automatic scaling and load balancing.
Seamless integration with Google Cloud services such as Cloud Storage and Cloud SQL.
Limitations:- Not specifically designed for machine learning pipelines.
Requires manual configuration and management of containers and dependencies.
AI Platform
Features:- Fully managed platform tailored for building and deploying machine learning pipelines.
Supports a wide range of machine learning frameworks and libraries.
Automatic hyperparameter tuning and model selection.
Integration with Google Cloud services such as Cloud Storage and Cloud SQL.
Limitations:- Limited support for non-machine learning workloads.
Requires manual configuration and management of pipelines and dependencies.
Key Differences
Purpose: Google Cloud Run is a general-purpose platform for building and deploying containerized applications, while AI Platform is specifically designed for machine learning pipelines.
Ease of Use: AI Platform provides a more streamlined and automated experience for building and deploying machine learning pipelines, whereas Google Cloud Run requires more manual configuration and management.
Scalability: Both platforms offer automatic scaling and load balancing, but AI Platform is optimized for large-scale machine learning workloads.
In summary, Google Cloud Run is an excellent choice for building and deploying general-purpose applications, while AI Platform is better suited for creating and managing machine learning pipelines.
Interested in learning how we are solving real business problems using AI? Learn more about our AI product on our website or contact us directly.
Interested in joining us and working on exciting and challenging problems in AI and machine learning? Send us a quick note with your LinkedIn profile link.


