
AI Feedback Loop: How It Works, Examples & Best Practices
An AI feedback loop is the process of feeding an AI system's outcomes, the corrections, ratings, and errors it produces in the real world, back into its training data so it improves over time. Instead of a model that is frozen after launch, a feedback loop turns every production mistake into a signal that makes the next prediction better. It is what separates AI that decays from AI that compounds.
Artificial intelligence is one of those things that feed on the ability to get better over time and is driven systematically by the application of feedback loops. Feedback loops help AI systems refine their performance by learning from outcomes—both successful and flawed. However, ai systems amplify biases through repeated cycles of learning from biased data or outputs, which can escalate existing prejudices and errors. This dynamic process of adjustment, especially when enhanced by generative AI, lies at the heart of modern machine learning. Generative AI enables the creation of sophisticated conversational bots and optimizes feedback loops to enhance the quality of AI outputs, addressing concerns around ‘model collapse’ that can arise from training on AI-generated content. This process can also lead to bias amplification, where feedback loops magnify pre-existing biases in the data, resulting in even more biased outputs over time. AI's influence extends beyond technical performance, shaping human judgment and decision-making through these feedback mechanisms. In particular, a real world AI system like Stable Diffusion can impact human perceptions and biases by disseminating generated images across social media and news platforms, further reinforcing feedback loops between AI and society.

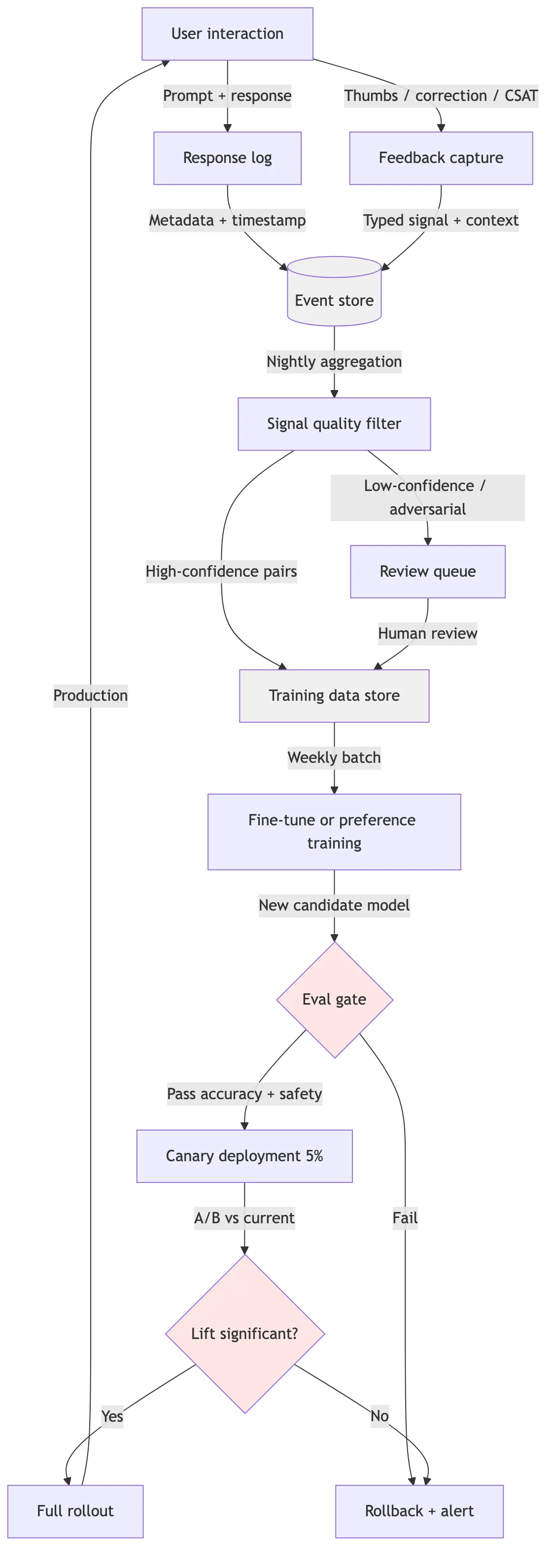
A production AI feedback loop, diagrammed
Most "feedback loop" content shows a cartoon arrow from output → human → better model. That skips the parts that actually break in production: aggregation cadence, signal quality, drift detection, and the gate between training and deployment.
The 6 feedback signals, ranked by signal-to-noise
Not all feedback is equal. Ranking from most-useful to most-noisy, with implementation difficulty:
Signal | Signal-to-noise ⚠ | Implementation difficulty | Drift risk | Best used for |
Explicit correction (user edits the AI’s response) | 9/10 | High — need an edit-capture UI | Low | Fine-tuning response quality |
Agent escalation (bot → human handoff with reason) | 8/10 | Medium — need structured escalation reason | Low | Identifying coverage gaps |
CSAT / post-interaction rating | 7/10 | Medium — survey plumbing | Medium | Overall model health |
Thumbs up/down | 5/10 | Low — one-click UI | High | Trend detection (not fine-tuning) |
Implicit: session abandonment | 4/10 | Low — passive logging | High | Negative-signal detection |
Implicit: follow-up-question (user asks same thing differently) | 3/10 | Medium — query-rephrase detection | High | Identifying confusion, not quality |
Rules of thumb:
Never train directly on thumbs data.
It’s noisy (sarcastic thumbs-ups, trolls, mis-taps) and the distribution skews negative because happy users don’t click. Use thumbs for drift dashboards, not labels.
Always train on explicit corrections when you can get them.
The ratio of edits to total responses is typically 1–3% ⚠, which is plenty for fine-tuning over a quarter.
Escalation reasons are free labels.
If your support agents pick from a dropdown when escalating, you already have gold-standard training data — most teams just aren’t shipping it back into the pipeline.
A minimal production feedback-loop pipeline (Python)
Below is a stripped-down but production-realistic pipeline. It collects feedback, filters for signal quality, and gates the output before training data is handed off to a fine-tune job.
from dataclasses import dataclass from datetime import datetime, timedelta from typing import Literal, Optional import hashlib SignalType = Literal[ "explicit_correction", "agent_escalation", "csat", "thumbs_up", "thumbs_down", "session_abandon" ] # Signal-to-noise weights from the taxonomy above. SIGNAL_WEIGHTS = { "explicit_correction": 0.90, "agent_escalation": 0.80, "csat": 0.70, "thumbs_down": 0.50, # thumbs_up is excluded entirely (see failure mode #2) "session_abandon": 0.40, } @dataclass class FeedbackEvent: request_id: str user_id: str prompt: str response: str signal: SignalType correction_text: Optional[str] # only set for explicit_correction escalation_reason: Optional[str] # only set for agent_escalation csat: Optional[int] # 1-5 timestamp: datetime def is_training_candidate(event: FeedbackEvent) -> bool: """Filter out events that would poison the training set.""" # 1. Drop thumbs_up entirely — happy users don't click, so this signal is biased. if event.signal == "thumbs_up": return False # 2. Drop events from known adversarial users (maintained elsewhere). if is_adversarial(event.user_id): return False # 3. For corrections, require a minimum edit distance so we don't train on typos. if event.signal == "explicit_correction": if levenshtein(event.response, event.correction_text) < 10: return False # 4. Drop stale events. Labels go bad when your model or product changes. if event.timestamp < datetime.utcnow() - timedelta(days=45): return False return True def to_training_pair(event: FeedbackEvent) -> dict: """Convert a validated feedback event into a (prompt, preferred, rejected) triple.""" weight = SIGNAL_WEIGHTS[event.signal] if event.signal == "explicit_correction": preferred, rejected = event.correction_text, event.response elif event.signal == "thumbs_down": preferred, rejected = None, event.response # preference learning needs a pair; drop to SFT-negative elif event.signal == "agent_escalation": preferred, rejected = None, event.response # human follow-up becomes the label downstream elif event.signal == "csat" and event.csat is not None and event.csat <= 2: preferred, rejected = None, event.response else: preferred, rejected = None, None return { "prompt": event.prompt, "preferred": preferred, "rejected": rejected, "weight": weight, "source": event.signal, "event_hash": hashlib.sha256(event.request_id.encode()).hexdigest(), } # --- Pipeline --- def build_training_batch(events: list[FeedbackEvent]) -> list[dict]: validated = [e for e in events if is_training_candidate(e)] pairs = [to_training_pair(e) for e in validated] pairs = [p for p in pairs if p["preferred"] or p["rejected"]] return pairs def gate_model(new_model_metrics: dict, baseline_metrics: dict) -> bool: """Eval gate — only promote if accuracy AND safety both hold or improve.""" acc_ok = new_model_metrics["accuracy"] >= baseline_metrics["accuracy"] - 0.005 halluc_ok = new_model_metrics["hallucinate"] <= baseline_metrics["hallucinate"] latency_ok = new_model_metrics["p50_ms"] <= baseline_metrics["p50_ms"] * 1.10 return acc_ok and halluc_ok and latency_ok
What to notice:
is_training_candidateis where most teams under-invest. Without it, a single adversarial user can poison a whole training batch.
The 45-day staleness cutoff is not arbitrary — it reflects how fast the underlying product changes. Shorter product cycles → shorter TTL.
gate_modelblocks promotion if hallucination rate went up
even if accuracy went up
. This is the single most important gate in the pipeline.
4 production failure modes (and how to fix them)
1. Reward hacking
Symptom: after a few feedback cycles, responses get shorter and vaguer. Thumbs-up rate stays high; CSAT drops.
Why: the model learns that shorter responses are less likely to be thumbs-downed. It’s optimizing the proxy (feedback) not the goal (helpfulness).
Fix: never train on a single signal. Combine thumbs with downstream CSAT and task-completion. And measure response length, diversity, and specificity as guardrails — alert if any drift >2σ.
2. Positive-feedback survivorship bias
Symptom: model quality degrades despite a rising thumbs-up rate.
Why: happy users close the tab; only dissatisfied users click thumbs. So thumbs-up rate measures engagement, not quality.
Fix: drop thumbs-up signals entirely from training (see the code sample above). Only thumbs-down is actionable.
3. Stale labels / product drift
Symptom: model’s accuracy on recent traffic drops even though training data looks clean.
Why: your KB, product, or pricing changed, but the feedback events from before the change are still in the training set, teaching the old answer.
Fix: timestamp every feedback event against a product-version ID. Discard any event older than the most recent schema change to the downstream data source. The 45-day cutoff in the code is a crude proxy — version-aware cutoffs are better.
4. Training/serving skew
Symptom: evals look great, canary passes, but production quality drops after full rollout.
Why: the eval set was built from curated examples. Production traffic is messier — malformed inputs, edge-case languages, unusual contexts the eval set never saw.
Fix: sample a frozen 5% slice of live traffic weekly. Use that as your eval set. Never hand-curate.
What is an AI Feedback Loop?
An AI feedback loop is a dynamic process where an artificial intelligence (AI) system receives feedback on its performance, uses that feedback to adjust its algorithms, and then receives more feedback. This continuous process of feedback and improvement is fundamental to machine learning, enabling AI systems to learn and adapt over time. By constantly refining their performance based on the data they receive, AI systems become more accurate and effective in their decision-making and actions. Feedback loops are crucial in ensuring that AI systems evolve and improve, much like how the human brain learns from experience, where human judgement plays a key role in interpreting feedback and guiding learning. The same feedback-loop discipline is what pushes automated ticket triage from 50% to 90%+ accuracy over time.
Understanding the Feedback Loop
A feedback loop in AI means the system’s outputs are evaluated and reintroduced into the system as inputs. Cycles allow the AI to discover patterns, correct errors, and recalibrate for better decisions by analyzing the quality of ai outputs. Just like a musician will perfect a melody from practice, AI is continuous refinement through repetition and tweaking.
Feedback loops are most observable in applications such as NLP, image recognition, and predictive analytics. For example, a chatbot that cannot accurately understand user intent will refine its algorithms using feedback for better accuracy in subsequent interactions. An image recognition system that mistakenly identifies a lion as a tiger will alter its model to enhance its identification of the same.
Mechanics of AI Feedback Loops

Five steps define how a feedback loop normally works:
Input Acquisition: The AI gathers information from sources like user interactions, sensor readings, or databases.
Processing and Analysis: The AI algorithm analyzes the inputs and identifies patterns and insights.
Output Generation: Based on the analysis, the AI produces results, whether recommendations, predictions, or classifications.
Feedback Collection: Results are compared to expectations. Errors or successes are pointed out by users, monitoring systems, or domain experts. In experimental or analytical contexts, error bars represent the variability or uncertainty in performance metrics when visualizing feedback loop outcomes.
Learning and Improvement: The AI adjusts its internal parameters, thereby fine-tuning its model to minimize errors and improve accuracy for future tasks.
This is a continuous cycle in which AI systems are constantly improving, becoming more efficient with each iteration.
Types of Feedback Loops in AI
Feedback loops in AI can be classified based on their purpose:
Positive Feedback Loops: These reinforce successful outcomes, enabling the AI to identify and replicate optimal behaviors. For example, a recommender system that successfully suggests a popular product uses this success to improve future recommendations.
Negative Feedback Loops: These address discrepancies by identifying and correcting errors. In an AI-based navigation system, negative feedback might involve recognizing incorrect route suggestions and updating the system to prevent similar mistakes.
AI Agent Feedback Loop
An AI agent feedback loop applies the same idea to autonomous agents that take actions, not just predictions. After an agent completes a task (resolving a ticket, processing a refund), the outcome and any human correction flow back in as reward or training signal. This is how agentic systems learn which multi-step workflows actually succeed, and where they tend to go wrong.
Machine Learning Feedback Loop
A machine learning feedback loop is the broader pattern underneath AI feedback loops: model predictions influence real-world data, which is then used to retrain the model. Done well, it improves accuracy. Done carelessly, it can amplify bias, because the model trains on data its own past behavior shaped. Guardrails (held-out evaluation, human review of edge cases) keep the loop healthy.
How AI Feedback Loops Work
AI feedback loops operate through a continuous cycle of observation, action, and evaluation. Initially, the AI system receives input from its environment, which could be user interactions, sensor data, or other sources. Machine learning algorithms then process this input to generate an output—referred to as the AI algorithm's response—such as a prediction, recommendation, or classification. The system then receives feedback on this output, which could come from users, human participants, monitoring systems, or domain experts. This feedback is used to adjust the AI’s algorithms, fine-tuning its model to improve future performance. The actual influence of this feedback determines how effectively the AI system learns and adapts over time, becoming more proficient in its tasks. In a working deployment, this cycle is what separates a demo from real AI for customer support — every resolved or escalated ticket becomes training signal for the next one.
Types of Feedback in AI Feedback Loops
There are several types of feedback that can be utilized in AI feedback loops, each with its own unique approach to enhancing the AI system’s learning process. The type and quality of feedback collected can also depend on the specific ai interaction condition, such as whether participants interact directly with AI, observe AI responses, or believe they are interacting with either humans or AI:
Supervised Feedback: Involves human input where labeled data is provided to the AI system. This helps the system learn from examples and improve its accuracy, often by comparing the AI's output to the human's own response to assess alignment and identify discrepancies.
Unsupervised Feedback: Does not involve human input. The AI system independently analyzes data to identify patterns and relationships, enhancing its understanding without explicit guidance.
Reinforcement Feedback: Rewards the AI system for correct actions and penalizes it for incorrect ones. This type of feedback encourages the system to learn optimal behaviors through trial and error.
Self-Supervised Feedback: The AI system generates its own feedback, often through self-play or self-exploration. This method allows the system to learn and improve autonomously.
As an example, in emotion recognition systems, feedback can be collected through an emotion aggregation task, where participants classify emotions from facial arrays, and their emotion aggregation response is analyzed to assess bias and the influence of AI or human interaction.
Each type of feedback has its strengths and weaknesses, and the choice of which to use depends on the specific goals and applications of the AI system. By leveraging these different types of feedback, AI systems can achieve a more comprehensive and robust learning experience.
Applications Across AI Systems
Feedback loops drive innovation in various AI applications such as:
Healthcare: AI systems improve diagnostic tools by learning from errors made in the initial medical evaluation, leading to measurable improvements in human accuracy when interpreting medical images or making clinical decisions.
Customer Support: Chatbots learn to understand the context and intent of a customer’s interaction through it, thereby enhancing human capabilities in delivering more effective and personalized support.
Autonomous Vehicles: Self-driving cars use feedback loops to improve object recognition and decision-making in real-time driving scenarios. For example, a self-driving car can adapt to various weather and road conditions by continuously learning and improving its performance through feedback loops, which also contributes to increased human accuracy in monitoring and intervening when necessary.
Feedback loops are instrumental in enhancing human capabilities across various domains by enabling both AI and humans to learn from each other and adapt. Performance improvements in these systems are often reflected in ai induced accuracy change and ai induced accuracy increases, demonstrating the positive impact of effective feedback mechanisms on both AI and human decision-making.
Feedback Loops in Customer Support

Customer support Feedback loopIn the customer service sector, feedback loops have evolved into an essential tool for the enhancement of service quality and efficiency. AI-powered chatbots and virtual assistants use these loops to continually improve their understanding of customer queries and responses. Large language models play a crucial role in enhancing the capabilities of these AI-powered chatbots by generating human-like interactions and improving operational efficiency. In many cases, participants perceived the influence of AI on the quality and fairness of responses, which can shape their trust in the system.
In other words, when a chatbot fails to answer a question from a user, then the interaction is marked for review. Support teams can analyze such cases to detect gaps in the training data or algorithm of the chatbot. This feedback helps retrain the AI model so that it can perform better in similar queries going forward. However, if feedback loops are not carefully managed, there is a risk of biased judgements being amplified, as AI systems may reinforce existing perceptual or social biases present in the data.
Moreover, feedback loops enable chatbots to adapt to evolving customer needs. By analyzing patterns in customer interactions, AI systems can identify emerging topics or frequently asked questions. These insights allow support teams to update the AI’s knowledge base and conversation flows proactively, ensuring that it remains relevant and effective.
Feedback loops also have a huge role in another area which is sentiment analysis. AI can analyze the tone, context, and emotion expressed in messages coming in from customers to gauge satisfaction levels. Such feedback has helped refine the ability of an AI system to handle sensitive issues with empathy and precision, thereby winning trust and improving customer experiences.
This will, in effect, improve the performance of AI while giving more power to businesses to have more personalized and responsive services that help customers improve loyalty and satisfaction.
AI Generated Content and Feedback Loops
AI-generated content is increasingly central to how modern AI systems learn and evolve through feedback loops. When an AI system receives input—whether from users, sensor data, or other sources—it processes this information to generate outputs such as text, images, or recommendations. These outputs, especially when they are AI generated content, become part of the feedback loop as users and experts provide feedback on their quality and relevance. This feedback is then used to refine the AI system’s algorithms, helping it learn from its mistakes and improve future performance.
In customer support, feedback loops are most effective when the AI is wired directly into the systems where tickets actually live — see our guide to the top CRM platforms for AI routing integration. This is one reason teams are shifting toward domain-specific LLMs for customer support, where the model is trained on the exact language, product terms, and ticket history of a single company rather than the open web. If the training data is biased or of low quality, the feedback loop can inadvertently reinforce errors or amplify existing biases within the AI system. This makes it essential for organizations to carefully curate and monitor both the original and AI generated content used in training, ensuring that feedback loops drive progress rather than perpetuate problems.
Mitigating AI Induced Bias
Addressing AI induced bias is a critical step in building fair and reliable AI systems. One of the most effective ways to mitigate bias is by ensuring that the training data used in feedback loops is diverse and representative of different perspectives and experiences. By incorporating a wide range of data sources, developers can help prevent the AI system from learning and subsequently amplifying biases that may exist in the data.
In addition to curating diverse training data, techniques like data augmentation and transfer learning can further enhance the quality and breadth of the data, reducing the risk of bias. Feedback loops that actively involve human input—such as expert review or user feedback—are also invaluable. These loops allow for the identification and correction of biased decisions made by the AI system, ensuring that any AI induced bias is caught and addressed early in the development process. By combining robust feedback loops with thoughtful data practices, organizations can create AI systems that are more equitable and trustworthy.
Best Practices for AI Development
Developing responsible and effective AI systems requires a commitment to best practices throughout the entire lifecycle. Central to this is the use of high quality training data that is both diverse and free from bias, forming the foundation for accurate and fair AI models. Implementing robust feedback loops is another essential practice, as these loops enable the AI system to learn from its mistakes, adapt to new information, and continuously improve its performance.
Transparency and explainability should also be prioritized, allowing stakeholders to understand how the AI system makes decisions and to trust its outputs. Regular evaluation of performance metrics, ongoing monitoring for bias, and the inclusion of human oversight in the feedback process all contribute to the development of AI systems that are not only effective but also ethical and reliable. By adhering to these best practices, organizations can harness the full potential of AI while minimizing risks and ensuring positive outcomes.
Challenges in the Implementation of Feedback Loop with Training Data
Although feedback loops are essential to the success of AI, they do not provide any easy answers. Challenging problems include noisy training data, under-resourced hardware, and the possibility that the model overfits it is trained on, creating an overly specific model as opposed to one that generalizes.
One major concern is model collapse, a phenomenon where AI systems degrade because they rely on low-quality or self-generated training data. This risk is exacerbated by the inclusion of ai generated content and ai generated data, which can contaminate training sets and lead to performance degradation. This underscores the importance of maintaining high-quality datasets and introducing robust safeguards against bias and data contamination.
Another critical risk is the presence of biased algorithm and biased algorithms, which can amplify existing biases through feedback loops. Studies have shown that biased AI and biased AI resulted in increased bias in human decision-making, as participants bias increased over repeated interactions with such systems. This creates a feedback loop where significant human bias and significant human bias relative to objective performance are observed, further distorting outcomes. Even a slight bias in the initial data or model can be amplified over time, leading to substantial effects. When evaluating performance and fairness, it is essential to consider gender groups and the impact of AI-generated images, such as financial managers generated by systems like Stable Diffusion, which often over-represent certain demographics. In data visualization and experimental results, thin grey lines are often used to represent subtle distinctions or overlays in figures, highlighting these disparities.
Statistical analysis of feedback loop outcomes should ensure that values remained significant and that significant p values are reported. The use of false discovery rate correction is necessary to control for multiple comparisons and ensure the robustness of findings. The quality of human data used for training and evaluation is also crucial, as it directly affects the outcomes of feedback loops and the potential for bias amplification.
Both the tendency for AI and human biases to interact and reinforce each other in feedback loops must be addressed. The accuracy of algorithms plays a key role: accurate AI and accurate AI resulted in improved human decision-making, while accurate and biased algorithms can have contrasting effects on feedback loop outcomes. How humans perceive AI systems and whether AI is labelled as human or non-human also impacts bias amplification and the dynamics of feedback loops, influencing social, emotional, and perceptual judgments.
Building Resilient Feedback Systems

Resilient systems
Organizations can optimize feedback loops by:
Maintaining high-quality, human-generated training datasets for periodic model recalibration. High quality training data is crucial to prevent model collapse and ensure continual improvement.
Introducing expert oversight to validate outputs and refine models.
Effective separation of real and synthetic training data would prevent model drift. Continuously incorporating new data helps in monitoring and adjusting AI systems to avoid distorted perceptions.
Evaluating performance using representative datasets ensures that models are robust against various inputs and fairly represent minority groups.
Considering the impact of stable diffusion on human judgment biases, especially in AI-generated images, to mitigate the amplification of existing social imbalances.
The Future of AI
Looking ahead, the future of AI is poised to bring transformative changes across industries, from healthcare and finance to education and transportation. As AI systems become more advanced and integrated into daily life, the importance of robust feedback loops and high quality training data will only grow. These mechanisms will be crucial in helping AI systems adapt to new challenges, learn from real-world interactions, and deliver increasingly accurate and valuable results.However, the future also brings challenges, such as the risk of AI induced bias, concerns about job displacement, and the need for strong cybersecurity measures. To navigate these complexities, it is essential to prioritize responsible AI development—ensuring that AI systems are designed with fairness, transparency, and societal benefit in mind. By fostering collaboration between developers, policymakers, and users, we can address these challenges and unlock the full promise of AI, creating a future where technology enhances human capabilities and drives positive change for all.
When NOT to use a feedback loop
Feedback loops aren’t free. There are three scenarios where they actively hurt:
Regulated outputs where every word is reviewed.
Legal, medical, compliance copy. If every response is human-reviewed before it ships, the signal from customer feedback is too noisy to improve the frozen prompt. Use A/B testing on prompt changes instead.
Adversarial user bases.
If >10% of your traffic is trying to jailbreak or manipulate, the feedback signal is pure poison. Lean on automated evals, not user feedback.
Very small sample sizes.
Fewer than ~500 validated feedback events per month? Statistical noise dominates. Wait until you have enough traffic to trust the signal, or batch quarterly.
For everything else — a support bot handling 10K+ tickets/month with a real escalation path — a tight feedback loop is the difference between a model that plateaus at 70% accuracy and one that hits 95% over two quarters.
Want to see a production feedback loop running? IrisAgent’s grounded support platform ships with the signal-quality filter, eval gate, and drift monitor from the code above already wired in. Book a 20-minute demo to see the pipeline operating on live customer data.
Conclusion
Feedback loops are the heart of learning, adaptation, and superiority in AI. The iteration process is taken on board by AI systems to not only correct mistakes made earlier but also find novel solutions to complex problems. Nevertheless, careful design and ethical considerations are needed to make sure that the feedback loop results in meaningful progress without losing fairness and reliability. The role of feedback loops will continue to play a key role in making AI more intelligent, responsive, and trustworthy as technology continues to advance.
At IrisAgent, Our Multi LLM powered engine has integrated the AI feedback loops to its very core. Book a personalized demo to see how our proprietary LLMs integrate feedback loops and make your customer support proactive.
Frequently Asked Questions
What is an AI feedback loop?
An AI feedback loop is a continuous cycle where an AI system's outputs are evaluated and fed back into the system as inputs, allowing it to identify patterns, correct errors, and improve its decision-making over time. It mirrors how humans learn from experience — each iteration refines the model's accuracy and effectiveness.
How does an AI feedback loop work?
An AI feedback loop works in five steps: the system acquires input data, processes and analyzes it to find patterns, generates an output (such as a prediction or recommendation), collects feedback by comparing results to expectations, and then adjusts its internal parameters to reduce errors. This cycle repeats continuously, making the system more accurate with each iteration.
What is the difference between positive and negative feedback loops in AI?
Positive feedback loops reinforce successful outcomes — for example, a recommendation engine doubling down on suggestions that users engage with. Negative feedback loops correct errors — for example, a navigation AI updating its model after suggesting an incorrect route. Both are essential: positive loops optimize what works, while negative loops fix what doesn't.
What are the four types of feedback used in AI learning?
The four main types are supervised feedback (human-labeled training data), unsupervised feedback (the AI discovers patterns independently), reinforcement feedback (rewards for correct actions and penalties for incorrect ones), and self-supervised feedback (the AI generates its own training signal through self-play or exploration). Most production AI systems use a combination of these approaches.
How do feedback loops improve AI customer support?
Feedback loops improve AI customer support by flagging failed interactions for review, retraining chatbot models on identified gaps, and adapting to evolving customer needs by analyzing interaction patterns. They also power sentiment analysis, helping AI detect tone and emotion in customer messages so it can handle sensitive issues with greater empathy and precision.
How can AI feedback loops cause bias, and how do you prevent it?
AI feedback loops can amplify bias when a model trained on biased data makes biased predictions, which then get reinforced through the feedback cycle. To prevent this, organizations should use diverse and representative training data, apply data augmentation and transfer learning, include human expert review in the loop, and regularly audit model outputs for fairness across demographic groups.
What is model collapse in AI?
Model collapse occurs when an AI system degrades because it is trained on its own outputs or low-quality synthetic data rather than diverse, human-generated data. Over successive training cycles, the model loses variability and accuracy, producing increasingly narrow or repetitive outputs. Preventing model collapse requires maintaining high-quality, human-curated datasets and clearly separating real data from AI-generated data.
What are best practices for building resilient AI feedback loops?
Key best practices include maintaining high-quality, human-generated training datasets for regular recalibration; introducing expert oversight to validate outputs; separating real and synthetic training data to prevent model drift; evaluating performance on representative datasets that include minority groups; and continuously monitoring for bias amplification across feedback cycles.
What is the role of feedback loops in machine learning?
Feedback loops are the core mechanism through which machine learning models improve. They enable a model to compare its predictions against actual outcomes, calculate errors, and adjust its parameters to reduce those errors in future predictions. Without feedback loops, machine learning models would remain static and unable to adapt to new data or changing conditions.
How do you implement a feedback loop in an AI system?
To implement an AI feedback loop, start by defining clear performance metrics, then build a pipeline that captures model outputs alongside ground-truth labels or user feedback. Use this data to periodically retrain or fine-tune the model, validate improvements on a held-out test set, and deploy the updated model. Automate this cycle with monitoring and alerting so degradation is caught early.
What is the difference between an AI feedback loop and a machine learning feedback loop?
A machine learning feedback loop is the broad pattern where model predictions influence real-world data that is then used to retrain the model. An AI feedback loop is the same idea applied to AI systems and agents in production, where corrections, ratings, and outcomes are fed back so the system keeps learning from its mistakes. In practice the terms are used interchangeably, with "AI feedback loop" emphasizing live, deployed systems.
What is an AI agent feedback loop?
An AI agent feedback loop applies the feedback principle to autonomous agents that take actions, not just predictions. After an agent completes a task, such as resolving a ticket or processing a refund, the outcome and any human correction flow back in as reward or training signal. This is how agentic systems learn which multi-step workflows succeed and where they tend to go wrong.


