OpenAI Realtime Audio for Customer Support: Build on GPT-Realtime-2 or Buy a Platform?
Building customer support voice AI on OpenAI’s Realtime audio API gives you the lowest per-minute cost and the most control, but it leaves you to build grounding, validation, telemetry, escalation, and helpdesk integration yourself. For most mid-market and enterprise support teams, a platform that federates GPT-Realtime-2 with hallucination removal and Zendesk-native routing reaches first call in days, not quarters. IrisAgent Voice AI runs on GPT-Realtime-2 today with validated accuracy above 95% across enterprise deployments including Dropbox, Zuora, and Teachmint.
This guide is for the engineering buyer evaluating “should we build voice support on the raw OpenAI Realtime API, or buy a platform that already wraps it?” It covers what OpenAI actually shipped, what the API does not give you, a concrete build-vs-buy framework, a working cost model, and where IrisAgent fits.
What OpenAI Actually Launched
OpenAI’s Realtime audio lineup now covers three workloads that customer support teams care about:
GPT-Realtime-2.
The conversational model. Speech in, speech out, with low-latency turn-taking. This is the model behind a real voice agent that can hold a multi-turn call.
Realtime-Translate.
Live translation across 70+ languages. The use case is bilingual or multilingual support without staffing native-speaker agents in every market.
Realtime-Whisper.
A transcription model tuned for the same Realtime pipeline. Lower-latency speech-to-text than the standard Whisper endpoint, designed for live call transcription and downstream QA.
All three plug into the same wss:// Realtime API surface and share the same tool-calling, function-calling, and event-stream model. So in theory, you can stand up a voice support agent with a single API key, a phone number from a telephony provider like Twilio, and a few hundred lines of code.
That demo works. The production version is a different conversation.
Why Engineering Teams Are Considering Build on Raw API
The pull toward building directly is real and it is rational. OpenAI’s Realtime API for customer support gives you four things a platform cannot:
The lowest possible per-minute floor.
You pay OpenAI’s audio rate plus your telephony cost. No per-resolution fee. No per-seat tax.
Full control of the prompt, tools, and turn logic.
No vendor between you and the model. Custom interruption handling, custom barge-in, custom escalation thresholds.
Direct access to new model versions.
When OpenAI ships GPT-Realtime-2.1 or a vertical-tuned model, you flip a string. You do not wait for a platform release.
No data routing through a third party.
For regulated workloads, the only parties on the wire are you, OpenAI, and your telephony vendor.
For a senior engineering team with budget, this looks like the obvious move. The CFO asks why you would pay platform markup on a public API. The CTO has a slide that says “build it ourselves in two sprints.” The first hello-world call works on a Friday afternoon. The decision feels made.
What the Realtime API Does Not Give You
This is the part the demo skips. OpenAI ships the model and the protocol. Everything between “the model said something” and “the customer hung up satisfied” is your problem. Specifically:
Grounding.
GPT-Realtime-2 will answer from training data unless you wire retrieval-augmented generation (RAG) yourself. Ungrounded large language models hallucinate on 15 to 30% of customer support responses, depending on query complexity (source: Stanford, 2024). On a voice call, a hallucinated refund quote, a fabricated policy, or an invented account state is heard, not read. The damage is immediate.
Hallucination validation.
RAG alone is not enough. You need a validator that checks every response against the source document it cites, before the bytes leave the server. IrisAgent’s Hallucination Removal Engine is exactly that layer. Building it from scratch is months of work and a permanent maintenance line.
Helpdesk integration.
Your support tickets live in Zendesk, Salesforce, Intercom, Freshdesk, or Jira Service Management. The voice call needs to read the customer’s account, write a case, attach the transcript, and route to a human when confidence drops. None of this is in the Realtime API.
Telephony glue.
SIP trunking, DTMF handling, call recording compliance, wiretap law per state and per country, after-call work, queue overflow. This is real infrastructure that takes a team.
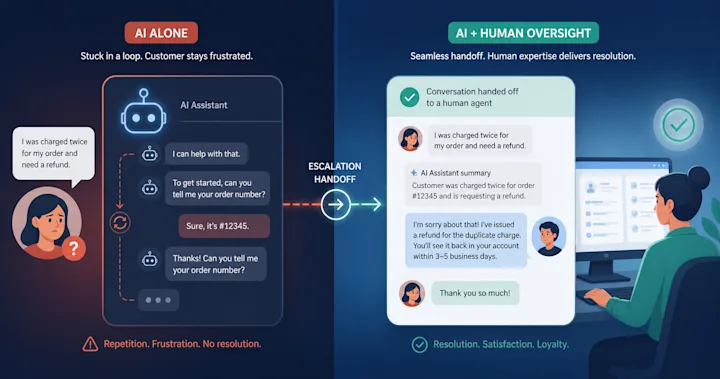
Escalation and human handoff.
When the model is uncertain, the call must transfer to a live agent with context attached. Building this safely requires confidence scoring, intent detection, and a fallback path that does not strand the customer in IVR purgatory.
QA and accuracy monitoring.
You cannot improve what you do not measure. Every call needs to be transcribed, scored against the resolution it claimed, and surfaced for review. Manual QA at 5% sampling will not catch drift.
Knowledge base management.
Your KB is in Confluence, Notion, Google Drive, or your helpdesk. The Realtime API does not ingest, chunk, embed, or refresh that content. You build the pipeline or you ship a static answer set.
Multilingual handoff.
Realtime-Translate is a model, not a workflow. Detecting language, routing to the right model, preserving context across a translated handoff, and reporting CSAT per language are all yours to build.
The OpenAI Realtime audio for customer support stack is the bottom 10% of a production voice agent. The other 90% is grounding, validation, integration, and the operations layer that lets a VP Support sleep at night.
Build vs Buy Decision Framework
Here is the framework we recommend to engineering buyers evaluating the OpenAI Realtime API for customer support. Walk through the seven questions in order. If you answer “yes, and we are funded to build it” to all seven, build. If any answer is no, buy.
Do you have a dedicated voice AI team of at least three engineers for the next 18 months?
Not “borrowed cycles from the platform team.” Three full-time people, plus a designated product owner.
Do you have a validated, refreshed knowledge base in a single source of truth?
If your KB is split across Confluence, Zendesk Guide, and a SharePoint folder nobody updates, you will ship a hallucination machine.
Can you justify the build to your CFO against a 24-hour deploy alternative?
The build path is six to nine months to a comparable production posture. The buy path resolves its first ticket the same day.
Do you have a hallucination validation strategy that is not “we will prompt-engineer it away?”
Prompt engineering reduces hallucination rates. It does not eliminate them. You need a validator layer.
Are you comfortable owning telephony compliance in every state and country you operate in?
Two-party consent recording laws, GDPR voice processing, HIPAA if relevant, PCI for any payment-adjacent call. Every one is a research project.
Do you have a plan for the next model release?
GPT-Realtime-2.1 will ship. Maybe a competitor’s model will outperform on your eval set. Are you ready to swap, A/B test, and roll back without a full re-platform?
Will support ops own the live agent without engineering tickets?
If every prompt change, every new SOP, and every escalation rule requires a deploy, the support team will work around the AI instead of with it.
Seven “yes” answers is a real build case. Most teams get to three or four and recognize they are about to recreate IrisAgent badly.
A Working Cost Model: Raw API Versus Platform
Engineering buyers like numbers, so here is a defensible model for a mid-market support team handling 500 voice contacts per day at an average handle time of 6 minutes.
Raw build on GPT-Realtime-2:
OpenAI Realtime audio cost: roughly $0.06 to $0.10 per minute of bidirectional audio at current rates, varying with the model tier and cache hit rate. Call it $0.45 per 6-minute call.
Telephony (Twilio or similar): $0.013 per minute inbound plus number rental. Call it $0.10 per call.
Engineering build cost: three engineers for six months at fully loaded $250K, plus ongoing 1.5 FTE for maintenance. Year one: ~$500K capex, $375K opex.
Hidden cost: the calls you lose during the build, the CSAT hit on early hallucinations, the helpdesk ticket about the hallucination, the agent minutes spent cleaning up. None of these show up on the OpenAI invoice.
Buy a platform that runs on GPT-Realtime-2:
Flat platform pricing tied to seats or volume, not per-resolution.
No engineering build cost.
24-hour deploy means first automated resolution on day one. The cost curve flips toward savings inside the first quarter.
The raw build looks cheaper on a per-minute basis and is more expensive on every other line. The break-even comparison is not API cost. It is total cost of ownership over 24 months, with the platform path almost always winning for teams under 5 million voice minutes per year.
How IrisAgent Voice AI Fits on Top of GPT-Realtime-2
IrisAgent Voice AI is the production wrapper that handles everything between GPT-Realtime-2 and a closed ticket. It is built on the OpenAI Realtime API for customer support, and it federates that model with Anthropic Claude, Gemini, and other frontier models so you are not locked to a single vendor.
The architecture has four layers:
Voice and transport.
GPT-Realtime-2 for conversation, Realtime-Translate for multilingual handoff, Realtime-Whisper for transcription and downstream QA. Telephony through your existing carrier or our native Twilio integration.
Grounding and validation.
Every response is generated against your knowledge base via RAG, then validated against the source it cites by the IrisAgent Hallucination Removal Engine before the audio is synthesized. This is how validated accuracy stays above 95% while ungrounded LLMs sit at 15 to 30% hallucination rates.
Helpdesk and ops layer.
Native installs into Zendesk, Salesforce, Intercom, Freshdesk, Zoho, and Jira Service Management. The voice agent reads the account, takes action through Smart Operating Procedures, writes the ticket, and hands off to a human when confidence drops below threshold.
AutoQA and accuracy monitoring.
Every call is transcribed and scored against the resolution it claimed. Drift surfaces in days, not quarters. This is the support operations layer that catches what manual sampling misses.
The result: a production voice agent that resolves real support work, runs on the same GPT-Realtime-2 you would have built on, and deploys in 24 hours instead of 24 weeks. See the Dropbox case study for what this looks like in production at scale, where IrisAgent saves 160,000 agent minutes and cuts average handle time by 2 minutes.
When Building Directly on the OpenAI Realtime API Is the Right Call
To be fair, the build path wins in a few specific scenarios. We tell engineering buyers to build directly when:
The use case is single-purpose and tightly scoped.
A one-question voice survey, a status check IVR replacement, an outbound appointment reminder. Anything that does not require multi-turn reasoning over a knowledge base.
You are an AI infrastructure company.
If voice AI is your product, you should own the stack. The platform abstraction is for buyers, not builders.
You have an existing in-house ML platform team with eval infrastructure.
Teams that already run continuous evals on a custom Claude or GPT pipeline are halfway there. The marginal cost of adding voice is much smaller than for a team starting from scratch.
Compliance forbids any third party on the data path.
Some defense, government, and healthcare workloads disqualify any wrapper layer. In that case you build, and you accept the timeline.
Outside these cases, the build-vs-buy math points at buy. The OpenAI Realtime API for customer support is a powerful primitive. Production support voice AI is an operations problem stacked on top of that primitive, and operations problems do not get cheaper because the API got better.
Next Steps
The OpenAI Realtime audio API for customer support is a real, working primitive. Three takeaways for the engineering buyer:
GPT-Realtime-2, Realtime-Translate, and Realtime-Whisper cover the audio layer. They do not cover grounding, validation, helpdesk integration, telephony compliance, escalation, or QA.
The build path takes six to nine months and a dedicated team of three engineers minimum. The buy path on a platform that runs on the same GPT-Realtime-2 deploys in 24 hours.
Total cost of ownership over 24 months favors a platform for any team under roughly 5 million voice minutes per year. The OpenAI invoice is the smallest line in the budget.
If you are evaluating the OpenAI Realtime audio for customer support today, the right next step is a working comparison. Run a 30-day pilot on your own ticket volume with IrisAgent Voice AI running on GPT-Realtime-2, measure validated accuracy, average handle time, and resolution rate against your current voice channel, then decide. Book a 20-minute demo to see the Hallucination Removal Engine in action on a live call.
Frequently Asked Questions
What is the OpenAI Realtime API and how does it differ from regular GPT-4 or GPT-5?
The OpenAI Realtime API is a websocket-based interface that streams audio in and audio out, with low-latency turn-taking suitable for live voice conversations. Regular GPT-4 and GPT-5 are text-based request-response APIs. The Realtime API wraps GPT-Realtime-2 (conversation), Realtime-Translate (live translation), and Realtime-Whisper (transcription) into a single audio-native stream, which is what makes a true voice agent possible without stitching three separate models together.
How much does it actually cost to run a voice support agent on GPT-Realtime-2?
The OpenAI audio rate is roughly $0.06 to $0.10 per bidirectional minute at current pricing, which translates to about $0.45 per 6-minute call. Add telephony at $0.013 per minute and you are at $0.55 per call before any engineering, integration, or grounding cost. The full total cost of ownership over 24 months almost always favors a platform for teams under 5 million voice minutes per year, because the unbuilt 90% of the stack costs more than the API itself.
Does GPT-Realtime-2 hallucinate on customer support calls?
Yes, if it is ungrounded. Stanford research from 2024 puts hallucination rates for ungrounded large language models at 15 to 30% on customer support workloads. On a voice call, a hallucinated refund quote or fabricated policy is heard immediately by the customer, so the cost is higher than for chat. The IrisAgent Hallucination Removal Engine validates every response against the source document it cites before the audio is synthesized, which keeps validated accuracy above 95% in production.
Can I build a Zendesk or Salesforce-integrated voice agent on the OpenAI Realtime API alone?
Not directly. The Realtime API ships the model and the audio protocol. It does not read your Zendesk tickets, write a case, attach a transcript, or transfer to a live agent with context. You build that integration yourself, or you buy a platform like IrisAgent that ships native installs into Zendesk, Salesforce, Intercom, Freshdesk, Zoho, and Jira Service Management.
How long does it take to build production voice support on the raw OpenAI Realtime API?
A demo that handles a single scripted call takes a long weekend. A production voice agent with grounding, validation, helpdesk integration, escalation, telephony compliance, and QA monitoring takes a dedicated team of at least three engineers six to nine months. IrisAgent Voice AI is in production on GPT-Realtime-2 in 24 hours, with the first automated resolution typically happening the same day as install.
What about Realtime-Translate for multilingual customer support?
Realtime-Translate is a strong primitive for live translation across 70 plus languages, but it is a model, not a workflow. You still need to detect the customer's language on call open, route to the right model, preserve conversational context across a translated handoff, and report CSAT per language. IrisAgent wraps Realtime-Translate inside the same Voice AI agent and ties it to the helpdesk so the translated transcript ends up on the right ticket.
Will building on GPT-Realtime-2 lock me into OpenAI?
It locks you into OpenAI for the model, the audio protocol, and the function-calling format. If you wire your integration tightly to the Realtime event stream, swapping to a competitor model is a non-trivial refactor. IrisAgent's federated multi-LLM architecture is designed for this exact problem, so you can run GPT-Realtime-2 today and swap to a different model when the frontier moves, without rebuilding the support stack.